
5 Data Science Buzz-Words You’re Still Not Clear About
Demystifying the most used and overwhelming Data Jargon

Data novices are flooded with jargon each new day. Personally, I have been overswept by coming in contact with these terms on a daily basis while working and learning. The shallow definitions would serve little to clear the concepts while already working on the pre-defined data track. If out of curiosity and annoyance of not knowing data-related terms you have been landed on this page. Let me not bore you more with my everyday short experiences while dealing with data. Let’s dive into the point!
1- Big Data
Big data nature is defined as the kind of data received in greater volumes; with different types and in huge quantities. To put it in layman’s terms, it’s the data that is ‘BIG’ and can’t be managed by traditional data processing software.
A) Volume:
The quantity of the data is humongous. This means handling both low and high dentistry of unstructured and structured data. The data sources can vary eg: from web pages, social media, or any clickstreams. The size of a large amount of data varies from ten terabytes to hundreds of petabytes.
B) Velocity:
It refers to the speed or rate at which the data is received or reacted upon. The highest speed of data that can be received is directly written into the memory, while low-speed data is kept on the disk. Some critical cases which require a real-time evaluation are written with the assistance of internet-enabled disks.
C) Variety:
The data available is diverse in nature ranging from conventional relational databases in the form of structured data to semi-structured and unstructured data. With the big data gaining momentum, there is a noticeable amount of unstructured in the form of video, audio, and text from which the meanings are derived.

Why use this data then?
Taking much pain for this kind of data must be certainly rewarding, this is why efforts are being done to understand and derive insights from it.
Big Data is an asset because of the values it provides. Companies use it o drive revenue opportunities, assist in resource management uplift operational efficiencies, and simplify smart decision making. Businesses, in particular, use big data to compute high-performance analytics that can help them manage risk portfolios within a few hours, and detect the causes of failure and anomalies in real-time.
2- Data Mining
It is an analytical process designed to study large data resources in search of regular patterns and systematic interrelationships between variables, and then to evaluate the results by applying the detected patterns to new subsets of data. The final goal of data mining is usually to predict customer behavior, sales volume, the likelihood of customer loss, etc.
The data mining process is targeted at businesses to assist them in running accurate campaigns, analyzing or predicting customer behaviors, and making smart market decisions. Just like miners dig mountains to access any resources, similarly With the data mininganalyst and scientists mine the data to extract useful information.
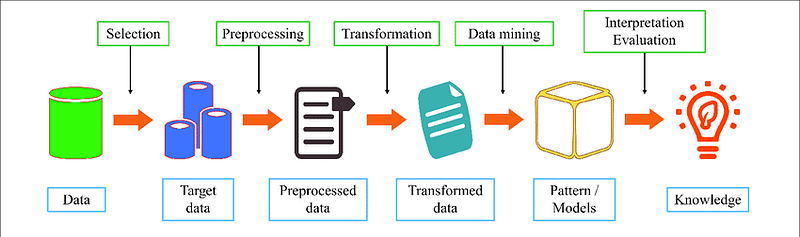
Collecting, Filtering, and analyzing the data to uncover involves searching, collecting, filtering, and analyzing the data to discover worthwhile insights, interrelationships, and patterns that sum up the fundaments of data mining.
3- Data Warehouse
It is a central location where the data of any enterprise gets stored because of a specific business requirement. After the ETL process(Extract-Transform-Load) data is stored in a central repository which is termed a data warehouse. It supports structured data and employs SQL queries for analysis. Which is then widely used in business intelligence, reporting, and market analytics for decision making.
To understand it better, it works on the principle of “Think first then load”. It implies that one needs to particularly understand the use-case or the goal, filter out the requirements and then use it.
In a data world, where one is bombarded with tons of unstructured data. Datawarehouse application would fail! There is also another core problem which includes it being fit for a certain type of applications only and is rigid.
This calls for some solution..? Let’s hop to another term that is considered by many people to tackle these limitations.
4- Data Lake
Have you ever seen a real lake? Data lake works on a similar concept. Just like in lakes different streams merge in their actual form. Similarly, in data lakes data in its raw natural form gets stored. One can also imagine it as a reservoir that stores without any pre-analysis of the data. Each item in the lake has a unique identifier, with its own set of metatags that can be used as a differentiator.

It works on “Load first think later” theory. Eg: Whenever a business query comes up, the data lake is searched for that set of information to be analyzed. It is particularly very useful for advanced data analytics and data science applications.
Data Lakes are highly agile and are still in a maturing phase. With all these advantages, the downsides of dataLakes can’t be neglected for sure. For instance, if the lake is being dumped by all sorts of data, it can easily be swamped and become just a muddle.
For this purpose, dataLake maintenance should include monitoring data source connections, proper meta-management, and updating ETL pipelines when required.
5- Data Mesh
Initially, big companies like Uber, Airbnb, Netflix, and Google were using microservice architectures. With the rise in domain-oriented businesses and designs, the ubiquity of adopting diverse data became a need.
This is how the trend of moving from monolithic architecture to a decentralized mesh came into play. The decentrailzied architecture allows greater accessibility, availability, and discoverability for interoperable data.
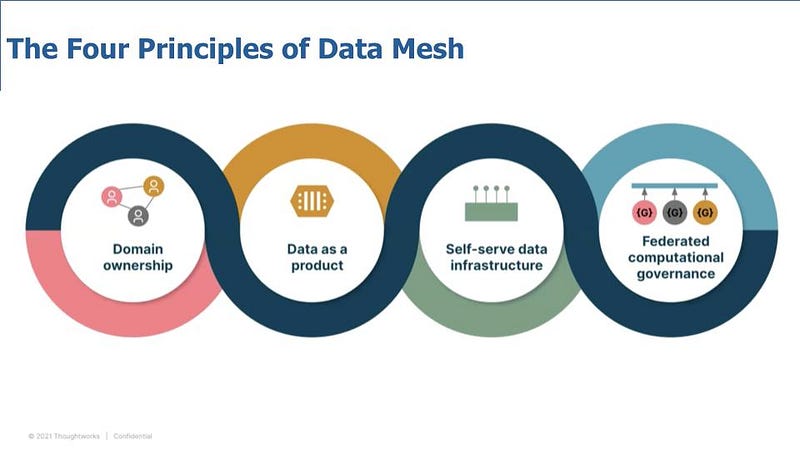
Data meshes satisfy the hunger of organizations to use more data than to rely on just a single department for data wrangling. Data meshes fit themselves perfectly in situations where there are complicated data pipelines and to assess the health of data during multiple lifecycles.
Subject For Thought
Don’t sell yourself short, if you were not equipped with the definition of these words in an interview or during some discussion. Understanding their theme concepts and having them implemented can have a substantial and outsized impact.
The data world is all interconnected and it is for one’s benefit if they tamp up their linking abilities. For instance, in two of the examples above Datawarehouse and DataLake are Relational and can exist at the same time. There is absolutely no comparison between them, I would prefer them both. I like datawarehouse because it offers me a built-in feature for direct data analysis without transforming or cleaning it.
However subject to the context if I want to predict future outcomes, and change some variables in the data set, I will opt for DataLake mainly because it's better at data visibility.
With that said, it's perfectly fine to build up your knowledge semantically without feeling overwhelmed by the data keywords your peers or colleague uses all the time.
Want to follow up more from me and other amazing writers on Medium?
Hop on the chance to join:





