
4 Top Spatial Machine Learning Algorithms You Should Learn In 2025
Machine learning algorithms are transforming the way we process and understand spatial data as geospatial analysis develops. This article covers the 2025 must-learn algorithms, such as Gaussian Processes, Random Forest, and K-Nearest Neighbors, which are propelling innovation in domains including disaster risk assessment, urban planning, and environmental monitoring.

Learn about the importance of these algorithms, their advantages, their uses, and how to become proficient with them to maintain your lead in the rapidly evolving fields of AI and geospatial technology. This article gives you the insights you need to solve challenging spatial problems, regardless of your level of experience.
Introduction
The development of geospatial analysis is continuing to transform data analysis in a number of industries as 2024 draws to a close and we turn to the coming year. We now see the world differently thanks to developments in agri-tech, satellite photography, and drones for decision-making. These advancements have been largely attributed to real-time analytics and artificial intelligence integration. The development of algorithms and the democratization of geospatial technologies are other important factors influencing the collection and analysis of geographic data.
Looking to 2025, I am excited to witness how AI-driven technologies will continue to revolutionize geospatial analysis, integrating multisource data and enhancing decision-making. As algorithms become more resilient and potent with the support of improved compute power, the synergy between artificial intelligence, machine learning, and geospatial analysis will usher in a new era of innovation.
In this article, I want to rank the ideal machine learning algorithms you should learn in 2025, as these algorithms have become very popular due to their versatility, efficiency, and ability to address complex geospatial and real-world challenges across industries. Please note that this list is in no particular order as they are all effective but some criteria’s have to be met.
2025 is all about data and decisions!
Algorithms and Spatial Analysis: A Special Blend
The combination of spatial analysis and machine learning algorithms produces a potent synergy that has the potential to revolutionize our comprehension and interpretation of geographical data. While algorithms provide the capacity to evaluate enormous volumes of data and reveal hidden patterns, spatial analysis usually entails looking at geographical patterns, correlations, and trends.
Geospatial data can be used to train machine learning algorithms, including convolutional neural networks, decision trees, and random forests, to recognize features, categorize different types of land cover, forecast environmental changes, and even spot abnormalities in satellite photos. This combination enables experts in domains such as disaster management, agriculture, and urban planning to make better.
This blend’s capacity to manage huge, intricate datasets is one of its main advantages. Machine learning algorithms can adapt to the growing volume and complexity of spatial data as it gets more varied and abundant. They can also handle the inherent ambiguity in geospatial data, record temporal fluctuations, and represent spatial interdependence.
These algorithms can more accurately and quickly evaluate multi-dimensional data, including raster and vector data, by utilizing deep learning techniques and sophisticated computer resources. Through more accurate and predictive spatial analysis, this creates new opportunities to solve global issues like resource.
The Machine learning market size is expected to show an annual growth rate (CAGR 2024–2030) of 36.08%, resulting in a market volume of US$503.40bn by 2030.
What to Consider for 2025
As stated earlier, certain requirements must be fulfilled, such as the project’s intended outcomes and the algorithm’s viability. Furthermore, consideration should be given to elements including the nature of the spatial data, scalability, interpretability, processing resources, and data complexity.
Understanding the dimensionality, amount, and quality of the data is another aspect of complexity. Assessing the algorithm’s capacity to manage time patterns, spatial interdependence, and the project’s particular domain requirements is also crucial.

Machine learning algorithms will impact various aspects of spatial analysis!
Some Other Factors Include
Project Objective: Determine whether the work entails classification, grouping, regression, or anomaly detection. Different algorithms work better on different types of jobs; you don’t need to be clear about your objectives when it comes to training, regression, or earth observation.
Goals: Ascertain which performance indicators — such as recall, accuracy, precision, F1 score, or computational efficiency — are most important to your project. Which timelines — that is, the project deadlines.
Algorithm Practicality: Consider the algorithm’s simplicity of use, the availability of libraries and tools, and the level of expertise required for implementation and optimization. What project are you working on?
Computational Resources: Assess the computational power at your disposal. Certain techniques may not be feasible for large datasets or real-time applications with limited processing capacity since they need a lot of resources.
Community & Support: Check the degree of community support and the documentation’s accessibility. Strongly supported algorithms often have a multitude of tools for troubleshooting and optimization.
Scalability: Confirm that the technique can handle growing amounts of data and be used in distributed systems if necessary. As the information expands or the project expands to bigger geographic areas, this guarantees the solution will continue to be dependable and effective.

Top ML algorithms for 2025
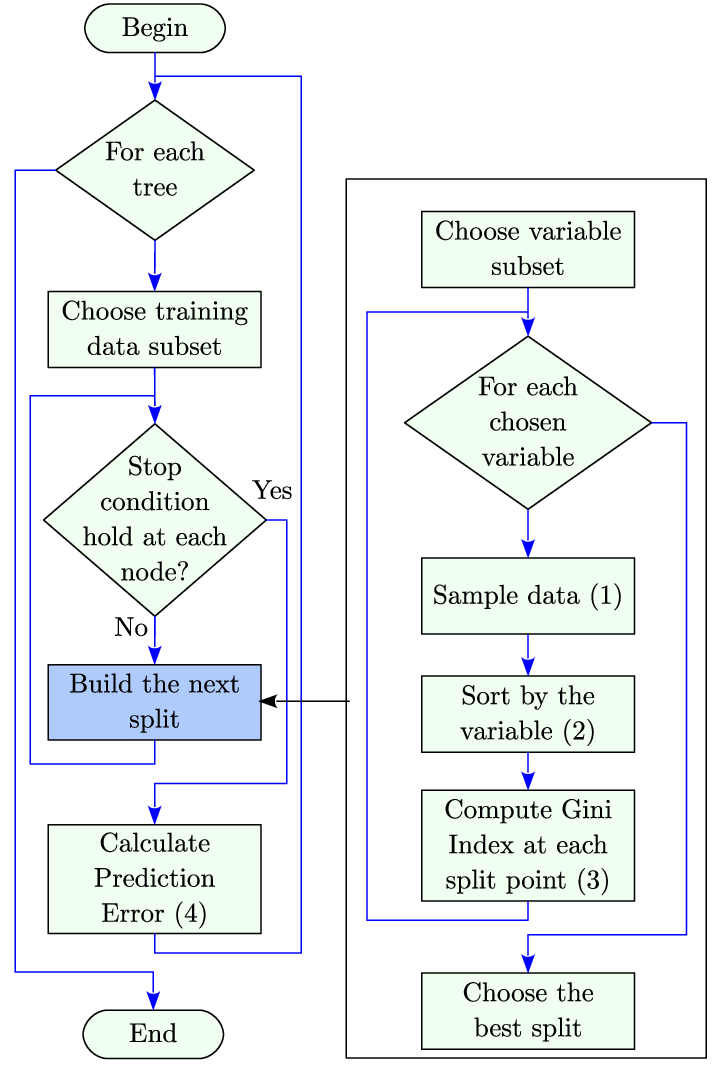
1. Random Forest
Random Forest can handle both classification and regression problems, it is a powerful and adaptable machine learning method that is frequently employed in geographic analysis. It is very useful for spatial data analysis since it generates a set of decision trees and aggregates their output.
Because it enables you to extract significant patterns from intricate, high-dimensional spatial datasets like satellite imagery, sensor data, and geographic features, learning Random Forest is essential.
Flow chart
Strengths
Robustness: Random Forest is appropriate for real-world geographic applications where data quality isn’t always flawless since it can manage noise, outliers, and missing data in datasets.
Feature Importance: It can automatically assess each feature’s significance, assisting in determining whether geographic factors — such as land use or vegetation type — have an impact on a particular result.
Nonlinear Relationships: When working with the intricate interactions seen in spatial data, it is crucial to be able to capture nonlinear relationships between input variables.
-Applications
Land Cover Classification: This method divides satellite or aerial photos into groups such as urban areas, waterways, and woods.
Environmental Monitoring: Using spatial data, it assists in forecasting environmental phenomena like pollution levels or habitat suitability.
Soil and Crop Analysis: Utilizing spatial data sources such as sensor networks and remote sensing, this technique can forecast crop yields, soil types, and other agricultural factors.
-How to Learn It
Books & Tutorials: Start with materials such as Aurélien Géron’s “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” or online guides that concentrate on Random Forest in geographical settings.
Hands-On Practice: Use tools like Kaggle or Google Earth Engine to work on real-world projects like classifying land using satellite photos or forecasting urban heat islands.
Courses: To obtain practical expertise with geospatial data analysis using Random Forests, enroll in courses like “Machine Learning with Python” or “Geospatial Data Science with Python”.
-Code snippet
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
# For classification
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train) # X_train: features, y_train: labels
# For regression
reg = RandomForestRegressor(n_estimators=100, random_state=42)
reg.fit(X_train, y_train)Random forest seems to take the cake.
2. K Nearest neighbor
K-Nearest Neighbors (K-NN) is a straightforward but powerful machine learning technique that is frequently applied to regression and classification problems. Because it clusters similar geographic features or classifies spatial data points according to their proximity to other points, it is very useful for geospatial analysis tasks like classifying land use. For those who are new to machine learning and spatial data science, K-NN is an excellent place to start because it is simple to comprehend and apply.
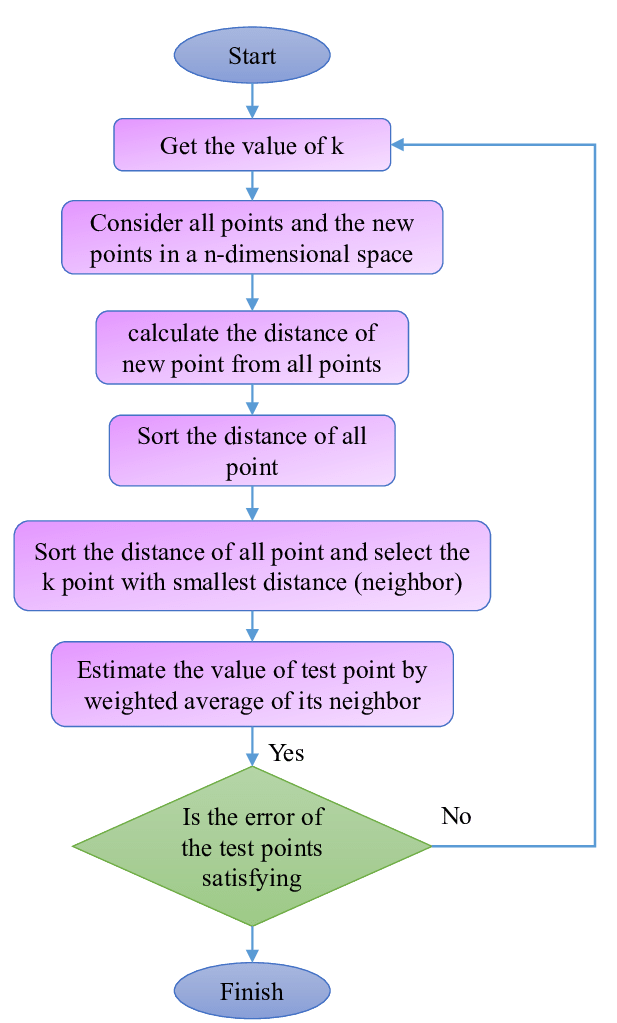
-Strengths
Simplicity: K-NN is easy to implement and interpret, making it an excellent entry-level algorithm for geospatial analysis.
No Training Phase: Unlike other machine learning algorithms, K-NN does not require a training phase, which can speed up the process of applying it to spatial datasets.
Versatility: It can handle both classification (assigning categories to spatial data) and regression (predicting continuous values, such as elevation or temperature).
-Applications
Land Use and Land Cover Classification: This method uses nearby named spatial data points to categorize different types of land cover (such as urban, forest, and water areas).
Urban Planning: Assists in locating locations with comparable urban features for planning objectives, such as areas with comparable green spaces or traffic patterns.
Environmental Monitoring: Using data from local sensors or the environment, this system forecasts environmental parameters like temperature, air quality, or pollution levels.
-How to learn
Books & Tutorials: For beginner-friendly instructions on K-NN in spatial analysis, look for materials like Sebastian Raschka’s “Python Machine Learning” or tutorials on websites like Medium.
Hands-On Practice: Work on geographical analysis tasks such as employing K-NN to find spatial clusters, classifying satellite imagery, or forecasting climatic data. Numerous datasets are available for testing on platforms like as Google Colab and Kaggle.
Courses: To comprehend the mathematical and computational underpinnings of K-NN, enroll in beginning machine learning courses like Andreas Müller’s “Introduction to Machine Learning with Python.”
code snippet
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
# For classification
knn_clf = KNeighborsClassifier(n_neighbors=5)
knn_clf.fit(X_train, y_train)
# For regression
knn_reg = KNeighborsRegressor(n_neighbors=5)
knn_reg.fit(X_train, y_train)3. Gaussian Processes (GPs)
Gaussian Processes (GPs) are a powerful, probabilistic machine learning method used primarily for regression and spatial modeling tasks.. Because they can model intricate, non-linear interactions between spatial points and provide a degree of prediction error, they are particularly well-suited for geospatial analysis. Because of its intrinsic flexibility and capacity to handle spatially correlated data, Gaussian Processes are widely used in domains such as environmental modeling, geostatistics, and geospatial forecasts.
Strengths
Uncertainty Quantification: GPs offer a confidence interval (uncertainty) in addition to forecasts, which is essential for making decisions in geographic contexts like environmental monitoring or risk management.
Non-linearity: GPs are very useful for geographical data, which frequently shows complicated spatial dependencies, because they can model complex, non-linear correlations between input variables, unlike linear regression.
Handling Spatial Correlation: GPs are able to consider the spatial correlation between data points, which is crucial for geospatial analysis because adjacent places frequently have comparable features.
Flexible Kernel Functions: GPs’ kernel function enables the model to be tailored to match particular geographic patterns, like gradual temperature fluctuations or sudden height shifts.
How to Learn It
Books & Tutorials: Examine works such as “Gaussian Processes for Machine Learning” by Christopher K. I. Williams and Carl Edward Rasmussen, which is a crucial resource for comprehending GPs. Step-by-step instructions can also be found in online tutorials like the Scikit-learn handbook.
Practical Projects: Work on initiatives that require geographical data, such mapping air quality levels or forecasting temperature swings within a region. Practice using GPs in practical situations by using publicly accessible geographical datasets.

Courses: To comprehend both theory and application, enroll in machine learning and geostatistics courses that address probabilistic models, such as Stanford’s “Probabilistic Graphical Models” or “Geostatistics with R.”
-Code snippet
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, ConstantKernel as C
# Define a kernel
kernel = C(1.0, (1e-3, 1e3)) * RBF(1.0, (1e-3, 1e3))
# Gaussian Process Regressor
gp = GaussianProcessRegressor(kernel=kernel, random_state=42)
gp.fit(X_train, y_train)
# Predict with uncertainty
y_pred, sigma = gp.predict(X_test, return_std=True)4. Spatio-Temporal Graph Neural Networks (ST-GNNs)
Why Learn?
State-of-the-art for examining spatiotemporal patterns in geographic data.
Strengths:
-Captures temporal and spatial correlations.
-Perfect for dynamic phenomena.
Applications
-Forecasting traffic flow.
-Identification of climate anomalies.
-Code Snippet
from torch_geometric.nn import GCNConv, RNN
class STGNN(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(STGNN, self).__init__()
self.conv1 = GCNConv(input_dim, hidden_dim)
self.rnn = RNN(hidden_dim, hidden_dim, batch_first=True)
self.fc = torch.nn.Linear(hidden_dim, output_dim)
def forward(self, x, edge_index, edge_weight, time_series):
x = self.conv1(x, edge_index, edge_weight)
x, _ = self.rnn(x, time_series)
return self.fc(x)Final thoughts
Practice — We are what we repeatedly do. Excellence, then, is not an act, but a habit. Aristotle
Learning machine learning algorithms such as Random Forest, K-Nearest Neighbors, and Gaussian Processes is becoming more and more important as the geospatial area develops. These algorithms enable analysts to confidently make data-driven judgments, solve intricate spatial problems, and unearth deeper insights. From managing large datasets to simulating spatial interdependence and forecasting results with specified uncertainties, each technique has special advantages.
In 2025, you may maintain your lead in the quickly developing field of machine learning and geographic analysis by mastering and using these tools. Gaining practical familiarity with actual geographical data is just as important as comprehending its theoretical underpinnings. The possibilities for creativity and significant solutions are endless as processing power increases and geospatial datasets become more complex.





