
Generative vs. Discriminative Models
We have all heard about generative models lately. Their capabilities for generating text, images, audio and video have shown truly stunning results during the last year. But what generative models really are and how do they differ from other types of machine learning models?
In general, classification models can be grouped under two broad categories: generative models and discriminative models. This article explains the difference between these two model types, and discusses the pros and cons of each approach.
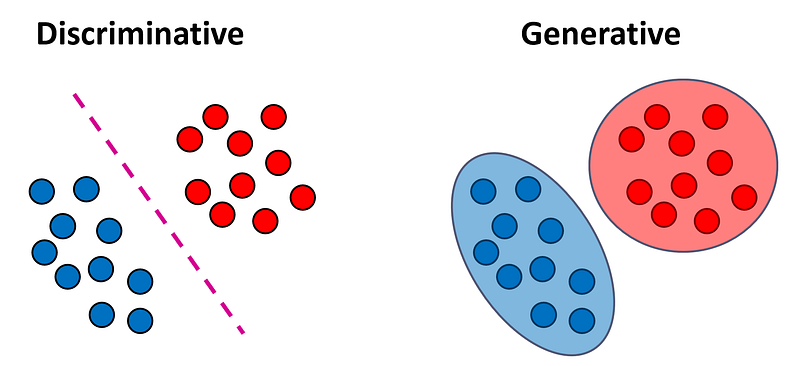
Discriminative Models
In classification problems, our goal is to assign each input vector x to a label y. Discriminative models try to directly learn the function f(x) that maps an input vector to a label. These models can be further divided into two subtypes:
- Classifiers that try to find f(x) without using any probability distribution. These classifiers output a label for each sample directly, without providing probability estimates for the classes. These classifiers are often called deterministic or distribution-free classifiers. Examples for such classifiers include K-nearest neighbors, decision trees and SVM.
- Classifiers that first learn the posterior class probabilities P(y = k|x) from the training data, and based on these probabilities assign a new sample x to one of the classes (typically to the class with the highest posterior probability). These classifiers are often called probabilistic classifiers. Examples for such classifiers include logistic regression and neural networks that use the sigmoid or softmax functions in the output layer.
All things being equal, we would rather have a probabilistic classifier than a deterministic one, since this classifier provides additional information about its confidence in assigning a sample to a specific class.
Generative Models
Generative models learn the distribution of the inputs before estimating the class probabilities.
More specifically, generative models first estimate the class-conditional densities P(x|y = k) and the prior class probabilities P(y = k) from the training data. In other words, they try to learn how the data was generated in each class.
Then, the posterior class probabilities can be estimated by using Bayes’ theorem:
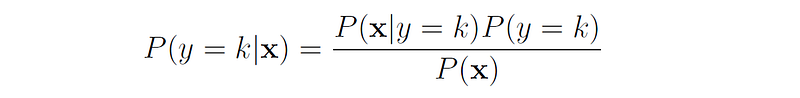
As usual, the denominator in Bayes’ rule can be found in terms of the variables appearing in the numerator:
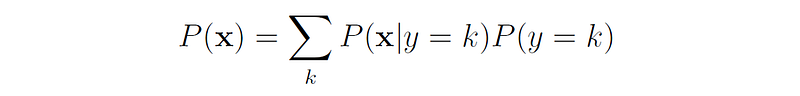
Alternatively, a generative model can first learn the joint distribution of the inputs and the labels P(x, y), and then normalize it to get the posterior probabilities P(y = k|x).
As before, once we have the posterior probabilities, we can use them to assign a new sample x to one of the classes (typically to the class with the highest posterior probability).
For example, consider an image classification task, where we need to distinguish between images of dogs (y = 1) and images of cats (y = 0). A generative model would first build a model of how dogs look like P(x|y = 1), and how cats look like P(x|y = 0). Then, to classify a new image, it will match it against both models to see whether the new image looks more like the dogs or more like the cats it has seen in the training set.
These models are called generative models, because they allow us to generate new samples from the learned input distributions P(x|y). For example, in our case, we can generate new images of dogs by sampling from P(x|y = 1).
Examples for generative models:
- Naive Bayes
- Gaussian mixture models (GMMs)
- Hidden Markov models (HMMs)
- Linear discriminant analysis (LDA)
Deep Generative Models
Deep generative models (DGMs) combine generative models and deep neural networks. Popular DGMs include:
- Variational autoencoders (VAEs)
- Generative adversarial networks (GANs)
- Auto-regressive models. For example, GPT (Generative Pre-trained Transformer) is an auto-regressive language model that contains billions of parameters.
These models will be covered in more detail in future articles.
Pros and Cons of Generative Models
Let’s examine the pros and cons of generative models as compared to discriminative models.
Pros:
- Generative models give us more information, since they learn both the input distribution and the class probabilities.
- Generative models allow us to generate new samples from the learned input distributions.
- Generative models can deal naturally with missing data, since they can estimate the input distributions without using the missing values. On the other hand, most discriminative models require all the features to be present.
Cons:
- It is computationally hard to learn the input distributions P(x|y) without making some assumptions about the data. For example, if x consists of m binary features, in order to model P(x|y) we need to estimate 2ᵐ parameters from the data for each class (these parameters represent the conditional probabilities of each of the 2ᵐ combinations of the m features). Therefore, a model such as Naive Bayes makes a conditional independence assumption on the features in order to reduce the number of parameters that need to be learned. However, such assumptions generally cause generative models to perform worse than discriminative models.
- Generative models are more sensitive to outliers, because outliers can have large effect on the input distributions. On the other hand, in discriminative models, outliers are just misclassified examples.
Thanks for reading!




