
3 Types of Missing Data and How to Handle Them(SQL examples provided)

There are three main types of missing data:
1. MCAR
MCAR stands for Missing Completely at Random. It is a type of missing data where the probability of a value being missing is unrelated to any of the variables in the dataset, including the missing data itself. In other words, the missing data is completely random.

Here are some examples of MCAR:
- A data collector accidentally drops a survey page.
- A participant in a medical study forgets to take their medication for a day.
- A sensor on a machine fails to record a value.
2. MAR
MAR stands for Missing at Random. It means that the probability of a value being missing is related to the observed data, but not to the missing data itself. For example, in a survey, respondents with lower education levels may be more likely to skip questions, but the specific questions that they skip are not related to the missing data.

Here are some examples of MAR:
- Respondents with lower education levels may be more likely to skip questions in a survey.
- People with more severe symptoms may be more likely to drop out of a clinical trial.
- Customers with lower satisfaction scores may be less likely to respond to a customer satisfaction survey.
MNAR stands for Missing Not at Random. It means that the probability of a value being missing is related to the missing data itself, even after accounting for the observed data. For example, in a medical study, patients with more severe symptoms may be more likely to drop out of the study, and their missing data may be more informative about their condition than the observed data.
3. MNAR
MNAR stands for Missing Not at Random. It means that the probability of a value being missing is related to the missing data itself, even after accounting for the observed data. For example, in a medical study, patients with more severe symptoms may be more likely to drop out of the study, and their missing data may be more informative about their condition than the observed data.

Here are some examples of MNAR:
- People with higher salaries may be more likely to refuse to participate in a survey about income inequality.
- Students who are struggling in a class may be more likely to skip the final exam.
- Patients with cancer may be more likely to drop out of a clinical trial if they are not responding to the treatment.
Here are some examples of MNAR:
- People with higher salaries may be more likely to refuse to participate in a survey about income inequality.
- Students who are struggling in a class may be more likely to skip the final exam.
- Patients with cancer may be more likely to drop out of a clinical trial if they are not responding to the treatment.
Identifying Missing Data
There are a number of ways to identify missing data in a dataset. One simple way is to look for empty cells or NULL values. Another way is to use statistical functions, such as the COUNT() function in SQL, to count the number of missing values in each column.
Rectifying Missing Data
Once we have identified the missing data in our dataset, we need to decide how to handle it. There are a number of different options, including:
- Imputing the missing values: This involves replacing the missing values with estimated values. There are a number of different imputation methods that can be used, depending on the type of data and the distribution of the missing values.
- Dropping the records with missing values: This involves removing the records from the dataset that contain missing values. This is a simple approach, but it can lead to a loss of information.
- Creating a new variable to indicate whether or not a value is missing: This can be useful for certain types of analysis, such as machine learning algorithms that are able to handle missing values.
The best approach to handling missing data will depend on the specific dataset and the analysis that is being performed.
Example: Identifying invalid employee records
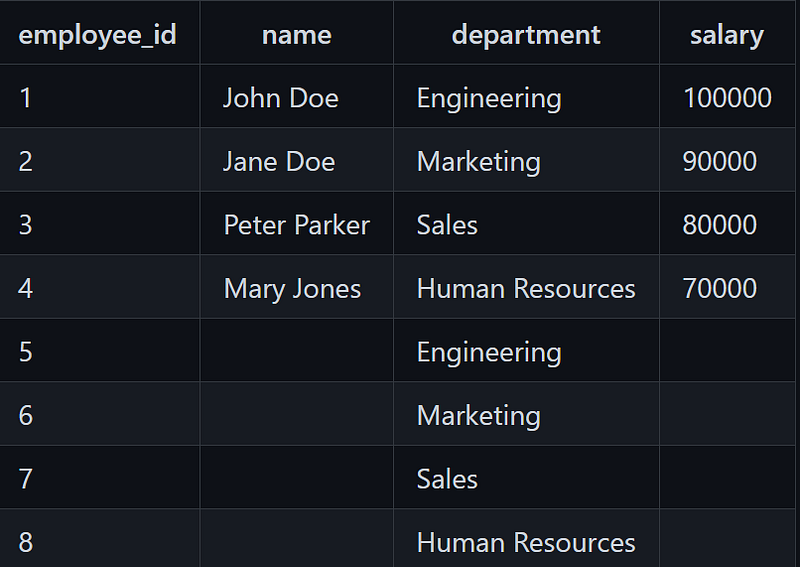
A human resources department is conducting an audit to ensure the validity of its employee records. The department has a table of employee records, with columns for employee ID, name, department, and salary. However, some of the records in the table are incomplete, with missing values in one or more columns.
The following SQL code can be used to identify missing data in the employee records table:
SELECT * FROM employees WHERE employee_id IS NULL OR name IS NULL OR department IS NULL OR salary IS NULL;This query will select all records in the employee records table where any of the columns are null. This will identify all of the incomplete records in the table.
Once the human resources department has identified the incomplete records in the employee records table, they need to decide how to handle them. There are a number of different options, including:
- Listwise deletion: This involves removing all of the incomplete records from the table. This is the simplest approach, but it can lead to a loss of data.
- Mean imputation: This involves replacing the missing values in the incomplete records with the mean value of the column. This is a quick and easy approach, but it can bias the results of the analysis if the missing data is not MCAR (missing completely at random).
- Median imputation: This involves replacing the missing values in the incomplete records with the median value of the column. This is a more robust approach than mean imputation, as it is less sensitive to outliers.
- Mode imputation: This involves replacing the missing values in the incomplete records with the most frequent value in the column. This is a simple approach, but it can bias the results of the analysis if the missing data is not MCAR.
The following SQL code can be used to rectify the missing data in the employee records table using mean imputation:
UPDATE employees SET salary = (SELECT AVG(salary) FROM employees) WHERE salary IS NULL;This query will update the salary of all employees with a missing salary to the mean salary of all employees. This is just one example of how to rectify missing data in employee records. The best approach will depend on the specific dataset and the analysis that is being performed.
Conclusion: In this article, we have discussed the three main types of missing data: MCAR (Missing Completely at Random), MAR (Missing at Random), and MNAR (Missing Not at Random). We have also discussed a number of different strategies for identifying and rectifying missing data, including listwise deletion, mean imputation, median imputation, mode imputation, and multiple imputation.
It is important to note that there is no one-size-fits-all solution to handling missing data. The best approach will depend on the specific dataset and the analysis that is being performed. It is also important to be transparent about how missing data has been handled, so that others can assess the quality of your results.





