3 AI and machine learning frameworks that Biden and Trump may use in the upcoming 2024 election
theories derived from the Cambridge Analytica scandal in 2016

Back in 2016, the Cambridge Analytica scandal erupted shortly after Trump’s victory in the 2016 US Election. It was the time where people started to feel the power of big data and machine learning and AI.
I will briefed sum up what has happened in 2016 election regarding the Cambridge Analytica-Global Science Research (GSR) scandal, what potentially was done with the data gathered by both companies and predict what would be the potential usage of AI and machine learning in the upcoming 2024 election.
The Cambridge Analytica scandal

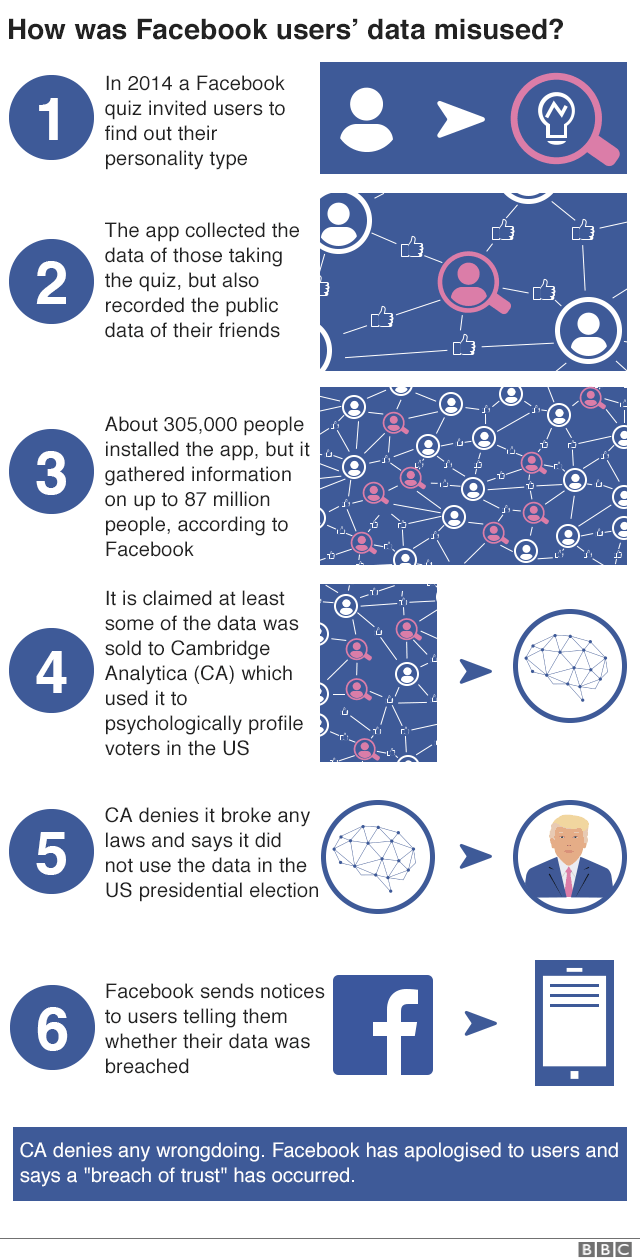
- In 2014, through Kogan’s company Global Science Research (GSR), in collaboration with Cambridge Analytica,over 300,000 of users were paid to take a personality test on Facebook via a Facebook app and agreed to have their data collected for academic use.
- the app also collected the information of the test-takers’ Facebook friends, leading to the accumulation of a data pool of over 80 millions personal information
- Facebook’s “platform policy” allowed only collection of friends data to improve user experience in the app and prohibited the sales of such data.
- 50 million of the data was suspected to have sold to Cambridge Analytica
- Cambridge Analytica says it uses “behavioral microtargeting,” or combining analysis of people’s personalities with demographics, to predict and influence mass behavior. It says it has data on 220 million Americans, two-thirds of the U.S. population.
How did the Cambridge Analytica achieve micro-targeting?
This might go a bit technical in this part. The actual algorithm was never revealed from the Cambridge Analytica nor the details of the actual data taken from the GSR. However, we could probably imagine what were needed in such process. Here are my speculations:
- Data
I deem the following data shall be necessary in performing micro targeting:
- Demographic information: Age, gender, location, education, etc.
e.g. Are young black voters in XXX state in favor of YYY candidate?
- Behavioral data: interests, online activity, and interactions.
e.g. Are tech-savvy persons in favor of XXX candidate?
- Social connections: Friend networks and affiliations
- Facebook Groups/ Facebook Page followed: determine your political preference
- Likes: what sentiment did you give on a specific topic/post
You may notice that these information are likely categorical (i.e. non-numeric) and requires further feature engineering which I would not go in full details making it too technical. In short, you can leverage a module called one-hot encoder in achieving the feature engineering
2. How? What is the machine learning framework potentially used by Cambridge Analytica?
It is likely that a combination of both unsupervised (only data features were given for classification purpose) and supervised learning (i.e. data with both features and target labels) were used.
- Unsupervised Machine Learning(Clustering):
=> Questions to ask: If a person is with XXX, YYY, ZZZ characters would he / she / they be grouped as AAA group or BBB groups??
- Cambridge Analytica likely used unsupervised learning techniques to group users with similar characteristics.
- Clustering algorithms (e.g., k-means, hierarchical clustering) could identify segments of users based on shared interests or behaviors.
- Clusters might represent political leanings, lifestyle preferences, or other relevant dimensions.
- For example, users who liked similar pages or exhibited similar online behavior could be grouped together.
2. Supervised Machine Learning (Predictive Modeling):
=> Questions to ask: continue from the result of Unsupervised Learning, does AAA or BBB groups has more likes (or positive comment) in any one of the candidates’ Facebook campaign pages?
- To predict individual behavior, supervised learning came into play.
- Cambridge Analytica likely built predictive models using labeled data:
- Target variable: number of likes in candidates’ Facebook campaign pages, or positive sentiment comment towards a candidate in this group
- Features: Demographics, interests, social connections, or classification result from the unsupervised learning, etc.
- Common supervised algorithms include:
- Logistic regression: Predicts binary outcomes (e.g., vote or not).
- Random forests, gradient boosting: Handle complex relationships.
- Neural networks: Capture intricate patterns.
3. What can you do with the result?
- Election is a money game, a precision in advertising could be helpful in campaign resources allocation
- If we have sufficient support in a certain group / certain states to win, reshuffle the resources to target other groups / states
- What are the heated topics in certain group? This could be helpful before the presidential debates (e.g. what voters hated most in your opponent? what are the most mentioned words with negative comment in your opponent?)
- You can also perform data exploration to compare the performance of each candidate. A sample project from MANCH HUI in Kaggle below is an excellent demonstration regarding the last election in 2020:
And now in 2024……
We have briefly gone through what happened in 2016, after almost 10 years technological advancement, with the popularity of Chat GPT, what could be possibly be done in the election in the current election?
Here are my speculations:
Prerequisite:
You need to have data in order to perform any analysis or running any machine learning code. The data in the 2016 incident was due to data leakage. Now, while the loophole is being sealed, can we find other ways to gather the data?
Now we are talking about web scraping where I have written another article earlier.
It is still possible to gather such data but requires more effort. For example, in Trump’s Facebook page, you could use selenium to look for:
- no. of likes in each post
- person(s) who liked such post
- the profile link of such person(s) [e.g. age, marital status]
- pages / persons followed by such persons (if such was made visible)
- populate 1–4 to form a meaningful dataset
We can do the same on X (Twitter), Instagram and Tiktok. As far as I know, these platforms do not offer user-friendly API for calling such data. So selenium is a better way to gather such data.
Possibility 1 — faster response on social media campaign and personalized calling
- with the advancement of cloud infrastructure such as AWS and Azure, data collection and CD/CI on machine learning are readily available to almost anyone
- speed and accuracy are greatly enhanced in the past years for machine learning
- Using the mined data and clustering from the unsupervised learning, you may see faster response on social media campaign. I speculate that presidential candidate may even inbox/ dm your Facebook or Instagram account for a more personalized calling!
Possibility 2 — misinformation / fake news by deepfake or other face swapping algorithm
It’s already happening now. Some readily available software allows anyone to swap the face of a video.
What candidate possibly could do is:
- create a deepfake video swapping the face of opponent on a speaker on sensitive issue
- using machine learning to compare the sentiment of voters before and after the video was released
- put a score on the effectiveness of the videos in terms of negative sentiment over time
- repeat another video with A/B test
- mass production on effective videos which passed the A/B test
Possibility 3 — geographic and image processing capability by Computer Vision
- use of satellite or drone image
- In a particular rally at open space, satellite images and drone images could be captured to perform the following:
a) how many people have attended the rally?
b) using a convolution neural network, determine the race of the attendees [a study was conducted on the feasibility here.] and compare the result in with second rally
c) using facial recognition to perform statistics on attendees’ sentiment based on their facial expression [related work here.]
d) compare the result from a) to c) with the data extracted via social media earlier. Does it tally your expectation?
Let say in area A, your initial study based on social media or other means of data collection suggest that older people are supportive to candidate Z, does the image of the rally at area A tally with your finding? Are there more happy elderly within the rally? If not, should you invest more to target these voters?
Conclusion
It is expected that data would flow faster and more robust in the coming 2024 Election. I think we will soon see a massive advertising campaign from the presidential candidates. When you see one, think and see if my speculation above are correct!





