Stable Video Diffusion Is Here — Stability AI’s Text/Image-To-Video AI Model

Today, Stability AI, the startup behind the popular open-source AI image generator Stable Diffusion, announced Stable Video Diffusion (SVD), an AI model that brings text or images to life by turning them into short videos.
What is Stable Video Diffusion?
Stable Video Diffusion takes an image or text prompt as input and outputs a smooth, multi-frame video clip that’s up to 4 seconds long. The interpolation between frames appears to be remarkably fluid.
There are two image-to-video models, SVD and SVD-XT capable of generating 14 and 25 frames, respectively, at customizable frame rates between 3 and 30 frames per second.
Both models support the following features:
- Text-to-Video
- Image-to-Video
- Resolution of 576 x 1024
- Multi-View Generation: Create videos from multiple perspectives
- Frame Interpolation: Smoothly transition between frames for seamless motion
- 3D Scene Understanding
- Camera Control via LoRA: Manipulate camera movements for cinematic effects
If you want to delve into the details of how SVD works, check out this research paper.
Example Videos
Stability AI showcased the capabilities of SVD with a series of captivating example videos on its announcement.

To me, these example videos look very cool. The interpolation between frames looks smooth, and the quality of the video is very decent.
How does it compare to competitors?
Currently, a handful of AI tools can generate videos from text or existing images. Two notable competitors are Runway’s Gen2 and Pika Labs. User evaluations have consistently ranked SVD’s image-to-video capabilities as superior in terms of overall quality.
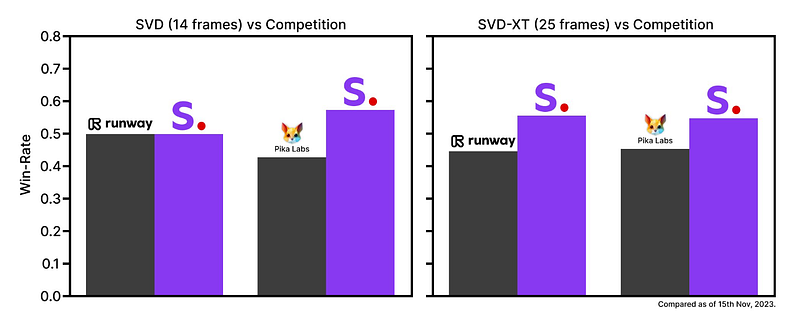
For in-depth details on the user study, refer to the accompanying research paper.
Multi-view synthesis
I was particularly impressed by the multi-view synthesis results—the potential to generate 3D objects from 2D images could be game-changing. Some users on X even posted their experiments to generate 3D objects with SVD.
How cool is that? An image-to-3D AI tool would be a game changer. Videos of basic 3D shapes showcase this capability, but we’ve yet to see how it handles more complex real-world scenes.
Current limitations
Of course, some limitations exist in these early versions. Here are some notable limitations for both SVD and SVD-XT:
- The generated videos are limited to 4 seconds only
- The models do not achieve perfect photorealism
- The model may generate videos without motion or very slow camera pans
- The model cannot render legible text
- Faces and people in general may not be generated properly
How To Get Access
SVD is still in research preview because it’s not yet intended for real-world applications.
While we eagerly update our models with the latest advancements and work to incorporate your feedback, we emphasize that this model is not intended for real-world or commercial applications at this stage.
Those eager to experiment can join the waitlist here, but a release date for wider access is still unknown.
Final Thoughts
I am happy to see the emergence of another text-to-video and image-to-video AI technology again after a period of slowed progress. The implications of this technology are immense—the ability to effortlessly animate our creative visions could revolutionize workflows across design, animation, VR, and more fields.
Imagine creating a full-blown film with no experience.
I hope innovators continue pushing boundaries even further in the coming weeks and months. Of course, this is an extremely difficult technical challenge, but the results we’ve seen with SVDS prove it’s possible.
I’m optimistic that with enough care, research, and responsible implementation, the positive impacts will be profound.
Related article:

This story is published on Generative AI. Connect with us on LinkedIn to get the latest AI stories and insights right in your feed. Let’s shape the future of AI together!