
20x times faster K-Means Clustering with Faiss
Benchmark time comparison between Scikit-learn and Faiss k-Means implementation

k-Means clustering is a centroid-based unsupervised method of clustering. This technique clusters the data points into k number of clusters or groups each having an almost equal distribution of data points. Each of the clusters is represented by its centroid.
For a set of n data points, k-means algorithms a.k.a Lloyd's algorithm optimizes to minimize the intracluster distance and maximize the intercluster distance.
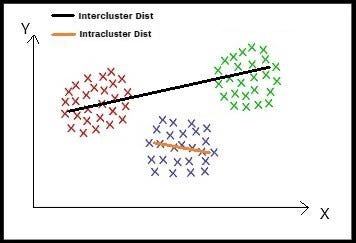
Read this article, to get a deep dive understanding of k-Means, k-Means++, and k-Medoids algorithm.
As per Wikipedia, The running time of Lloyd’s algorithm is O(nkdi)where:
n is the number of instances in the dataset
d is the dimensionality of the vector
k the number of clusters
i the number of iterations needed until convergenceScikit-learn package comes with the implementation of k-Means clustering algorithm According to the scikit-learn documentation the average time complexity of implementation of the k-Means algorithm is O(nki) .
In general practice, the k-Means clustering algorithm is one of the fastest clustering algorithms. When it comes to the cluster a large-size dataset scikit-learn package takes a lot of time to implement the algorithm. This article will discuss k-Means implementation using the Faiss library and compare the benchmark time numbers for training and prediction of the algorithm.
Faiss:
Faiss is an open-source Python package developed by Facebook AI Research for efficient similarity search and clustering of dense vectors. Fiass can implement algorithms for datasets of any size, including those that can not fit into the RAM. Faiss is written in C++ with complete wrappers for Python. Faiss also comes with implementation to evaluate the performance of the model and further tuning the model.
Scikit-learn vs Faiss:
Scikit-learn is a popular open-source Python package that comes with the implementation of various supervised and unsupervised machine learning algorithms. One must need to tune the hyperparameters for both the model to train a specific model. The hyperparameters of k-Means clustering include the number of clusters, number of restarts (each starting with other initial guesses), and maximal iterations.
The core of the k-Means involves searching for nearest neighbors, specifically nearest centroids, both for training and prediction. Faiss comes up with the optimized implementation of the nearest neighbor search algorithm. That's where the Faiss implementation is comparatively faster compared to scikit-learn. Faiss leverages GPU support and C++ implementation for faster implementation of the algorithm.
Faiss implementation with Scikit-learn:
Benchmark Time Comparison:
System configuration: Intel I7 (7th Gen), with 16GB of RAM
All the below-mentioned datasets can be downloaded from Kaggle.
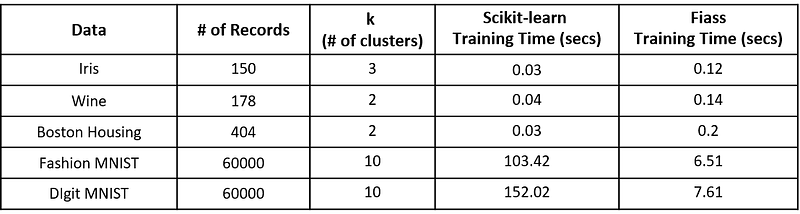
Observing the above time numbers calculated for the various datasets, the performance of the scikit-learn k-Means model is better compared to Faiss's implementation. For the large-size datasets, Faiss is the clear winner. k-Means implementation with Faiss is almost 20x times faster than that of scikit-learn. However, if GPU support is used, the performance of Faiss would further increase for the large-size datasets.
Conclusion:
In this article, we have discussed the implementation of the k-Means clustering algorithm using the Faiss package. From observing the above benchmark time comparison, we can conclude that for a large-size dataset Faiss's performance is far better than that of scikit-learn implementation. The prediction time of k-Means clustering models is optimized for Faiss compared to scikit-learn.
Read the below-mentioned article, to get a deep dive understanding clustering algorithms:
- Understanding K-Means, K-Means++ and, K-Medoids Clustering Algorithms
- How to Improve the Interpretability of k-Means Clustering Algorithm
- Fuzzy C-Means Clustering — Is it Better than K-Means Clustering?
References:
[1] Faiss Documentation: https://github.com/facebookresearch/faiss
Thank You for Reading



