
(2/2) Fastai, the new radiology tool
This article is part of the “Deep Learning in Practice” series.
Read the part 1: “(1/2) Fastai, the new radiology tool”.
Abstract
MURA is a dataset of bone X-rays that allows to create models that find abnormalities. Fastai v1 allows to create such a world-class model as part of the MURA competition, which evaluates the performance of a study classifier using the kappa score.
In part 1, we applied the standard fastai way of training a classification Deep Learning model on two pre-trained ones (resnet34 and densenet169), which allowed us to obtain a kappa score of 0.642. In this part 2, we sought to optimize the training of the densenet169 model and we managed to achieve a better kappa score of 0.674.
Based on our work and our results, we highlight 3 points regarding the use of Deep Learning with medical images: need for a fast GPU, use of ensemble models and necessary medical skills to create a professional medical application.
[+] Code in jupyter notebook [+] nbviewer of the notebook
Network architecture and Training
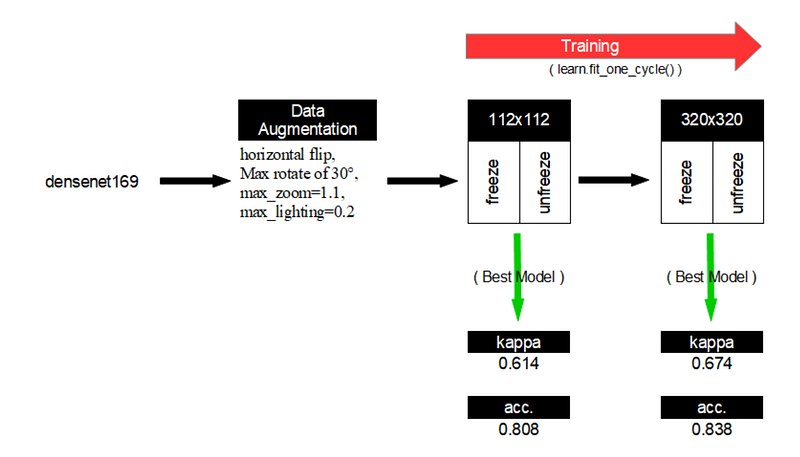
In this part 2, we have kept the densenet169 model used in the MURA paper but we have trained it with the following parameters and process (when a specific fastai technique was used, it is written “(fastai)”):
- Use of the densenet169 model pre-trained on ImageNet.
- (fastai) Firstly, we trained our model with input images of size 112x112.
- Then, we trained our model with input images of size 320x320 as done in the paper.
- (fastai) For each input images size, we firstly trained the freeze version of the model, and then the unfreeze one.
- Data Augmentation (DA): horizontal flip and max rotate of 30° without wrap.
- (fastai) In relation to DA, we also used the default fastai transformations as
max_zoom=1.1andmax_lighting=0.2through the get_transforms() fastai function. - (fastai) Training of the model with the function
fit_one_cycle()that uses Adam with default parameters. Augmentation of the weight decay to wd=0.1 and use of the callback functionSaveModelCallback()in order to save the model after an epoch if its kappa score is the biggest. - First Learning Rate: use of the function
lr_find()to get the best learning that is decayed by a factor of 10 each time the validation loss plateaus after an epoch. - Batch size: 8 as done in the paper.
Excerpts from the MURA paper about the network architecture and training:
We used a 169-layer convolutional neural network to predict the probability of abnormality for eachimage in a study. The network uses a Dense Convolutional Network architecture — detailed in Huanget al. (2016) — which connects each layer to every other layer in a feed-forward fashion to make theoptimization of deep networks tractable. We replaced the final fully connected layer with one that has a single output, after which we applied a sigmoid nonlinearity.
Before feeding images into the network, we normalized each image to have the same mean and standard deviation of images in the ImageNet training set. We then scaled the variable-sized images to 320×320. We augmented the data during training by applying random lateral inversions and rotations of up to 30 degrees.The weights of the network were initialized with weights from a model pretrained on ImageNet (Deng et al., 2009). The network was trained end-to-end using Adam with default parameters β1=0.9 and β2=0.999 (Kingma & Ba, 2014). We trained the model using minibatches of size 8. We used an initial learning rate of 0.0001 that is decayed by a factor of 10 each time the validation loss plateaus after an epoch. We ensembled the 5 models with the lowest validation losses.
Musculoskeletal radiographic studies
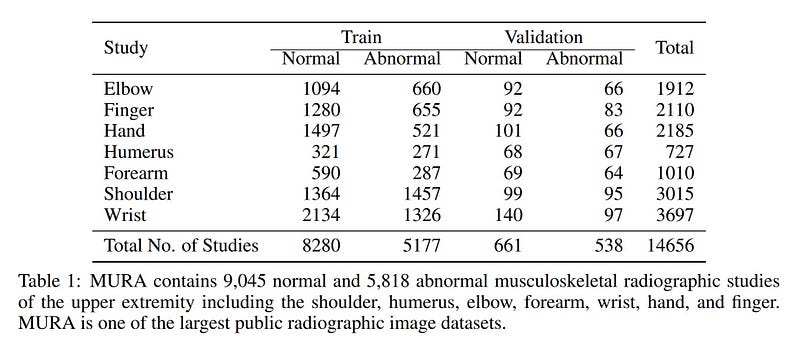
Neither the training set, nor the validation one are balanced but the ratio (about 60/40 for the training set, 80/20 for the validation one) with the use of Data Augmentation techniques (rotation of 30 degrees, horizontal flip, zoom of 1.1, change of brightness/contrast) when training the model should not be very troublesome.
Note: in fact, we tested a weighted loss function but it did not bring improvements.
Performance
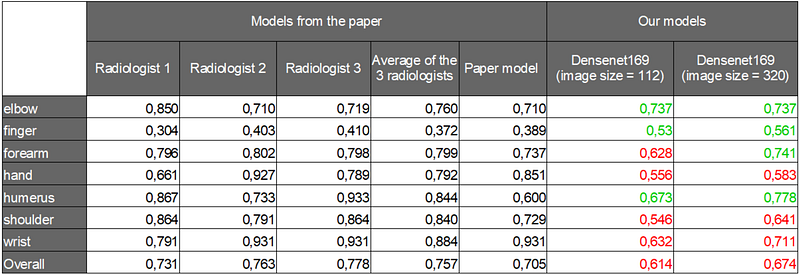
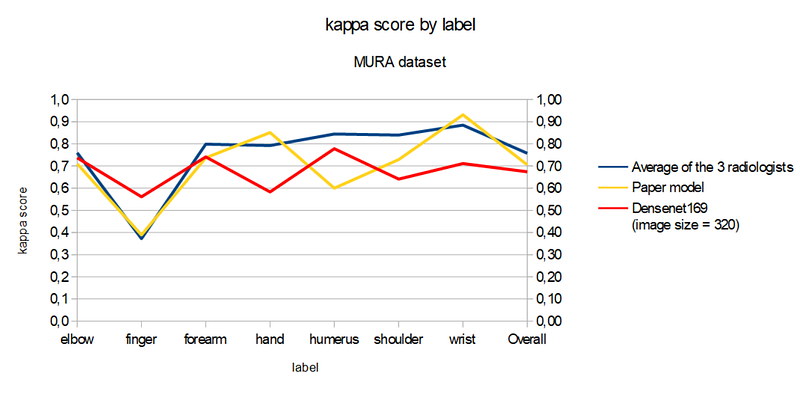
In the following table and chart, we can see that our model with 320x320 image size gets a better kappa score than the paper model in 3 categories (elbow, finger and humerus) and in one category compared to the average radiologists kappa score (finger).
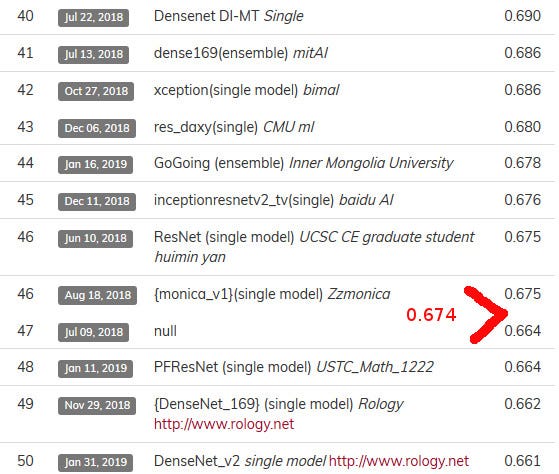
We performed reasonably well (47 out of 67 participants) but we did not achieve the overall kappa score of the paper model (0.705) despite many trials from the same pre-trained model (densenet169). It would be interesting if the authors of the paper could publish their code or other users of fastai take back our notebook to improve it.
More about the results by model
Step 1 | Input images size of 112x112
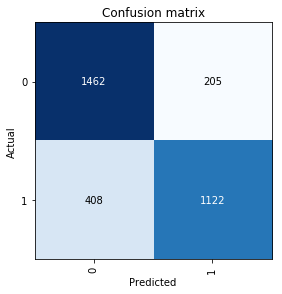
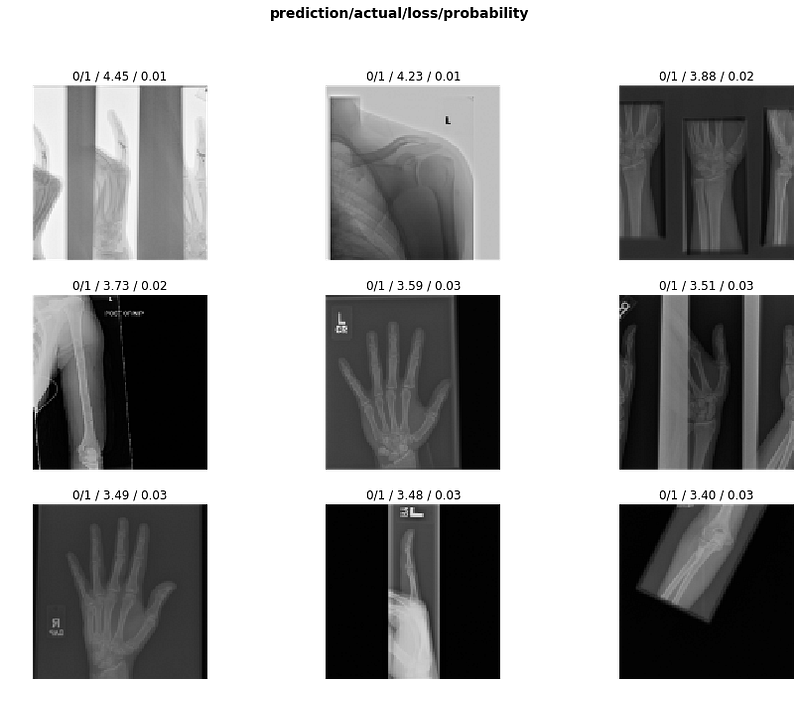
Step 2| Input images size of 320x320
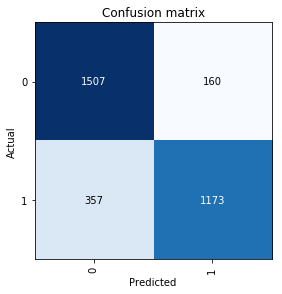
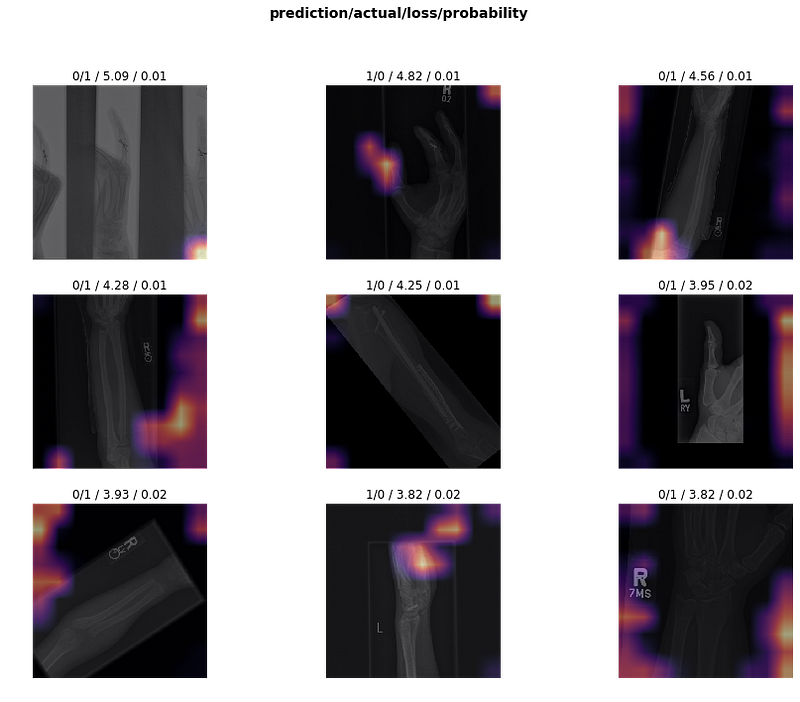
Conclusion
Our experience with the MURA dataset brings us to highlight the following points:
- Training a model of DL with medical images requires many tests (the choose of the right parameters and hyperparameters) and without a fast GPU, it takes several days to get a result (we used an NVIDIA Tesla P4 GPU on GPC).
- According to the participants with the best kappa scores, it seems that such a model consists of taking the average of several models scores (ensemble model). That’s what the paper does by saying “ We ensembled the 5 models with the lowest validation losses”, but without any information about these 5 models.
- The lack of knowledge of the field of medical imagery (our case) is not a problem to obtain a model of good level but this medical knowledge becomes necessary to create a professional level application.



