
Vision-centric Semantic Occupancy Prediction for Autonomous Driving
A review of the academic “Occupancy Networks” as of 2023H1
One critical pain point of existing 3D object detection methods in autonomous driving is that they typically output concise 3D bounding boxes, neglecting finer geometric details and struggling to handle general, out-of-vocabulary objects. This pain point exists for both monocular 3D object detection and BEV multicamera object detection. To address this problem, Occupancy Network, a vision-centric solution for general obstacle detection was first introduced in a keynote speech by Tesla in CVPR 2022 and later popularized by AI Day 2022. For more details, please refer to the previous blog post series on drivable space.
In academia, the equivalent perception track to Occupancy Network is known as Semantic Occupancy Prediction (SOP) and is sometimes also referred to as Semantic Scene Completion (SSC), with some subtle differences between the two explained below. Semantic occupancy prediction assigns the occupancy state and semantic label to each voxel in the scene. This is a representation general and expressive enough to describe objects of known classes but with an irregular shape or objects out of the known white list. This blog post will review the state-of-the-art methods of semantic occupancy prediction as of early 2023. This area has received intense attention in academia, evidenced by an explosion of papers submitted to top conferences, and there is also an occupancy predicting challenge at this year’s CVPR.
Semantic Scene Completion vs Semantic Occupancy Prediction
The concept of semantic scene completion (SSC) was first proposed in the SSCNet paper (CVPR 2017) and later popularized by SemanticKITTI (ICCV 2019), which provided an official dataset and competition track. More recently, a slightly different task semantic occupancy prediction (SOP) emerged. Both SSC and SOP aim to predict the occupancy status and semantic class of a voxel in a given spatial location, but there are several subtle differences. First, the input modality for SSC is partial 3D data collected by LiDAR or other active depth sensors, hence the name “completion” of a 3D semantic scene. SOP uses 2D images, possibly multicamera and multiframe, as input. In addition, SSC typically focuses on static scenes while SOP can handle dynamic objects as well. In summary, SOP seems to be a more general and preferred terminology, and in this article, we will use Semantic Occupancy Prediction, Semantic Scene Completion, and Occupancy Network interchangeably.
The pioneering work of monoScene first uses monocular images to conduct the semantic occupacny prediction task on SemanticKITTI. It still refers to the task as SSC, perhaps due to the fact that SemanticKITTI contains mostly static scenes. Later studies prefer the term SOP which expands the task to other dataset such as NuScenes and Waymo and handles dynamic objects as well.
High-level summary of the pioneering works
Here I will first summarize the explosion of research studies during the past year on a high level, and then follow up with a summary of the various technical details. Below is a diagram summarizing the overall development thread of the work to be reviewed. It is worth noting that the field is still rapidly evolving, and has yet to converge to a universally accepted dataset and evaluation metric.
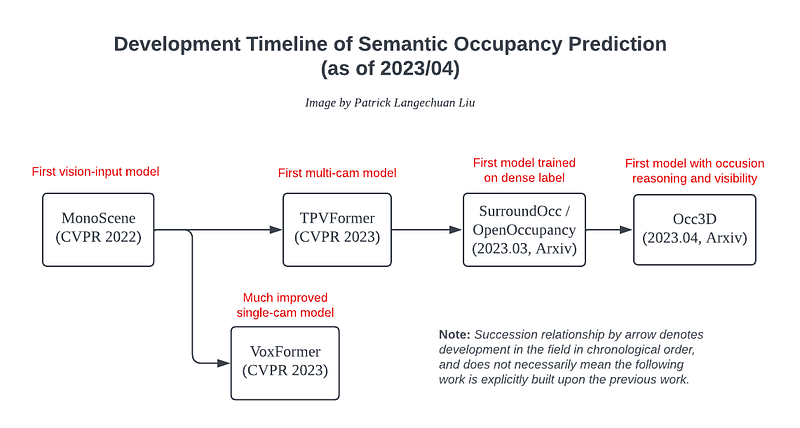
MonoScene (CVPR 2022), first vision-input attempt
MonoScene is the first work to reconstruct outdoor scenes using only RGB images as inputs, as opposed to lidar point clouds that previous studies used. It is a single-camera solution, focusing on the front-camera-only SemanticKITTI dataset.

The paper proposes many ideas, but only one design choice seems critical — FLoSP (Feature Line of Sight Projection). This idea is similar to the idea of feature propagation along the line of sight, also adopted by OFT (BMVC 2019) or Lift-Splat-Shoot (ECCV 2020). Other novelties such as Context Relation Prior and unique losses inspired by directly optimizing the metrics seem not that useful according to the ablation study.
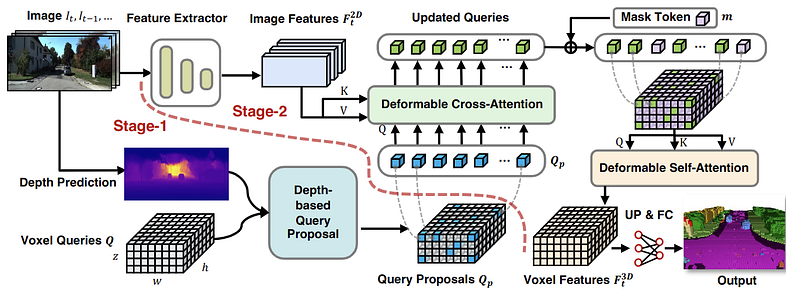
VoxFormer (CVPR 2023), significantly improved monoScene
The key insight of VoxFormer is that SOP/SSC has to address two issues simultaneously: scene reconstruction for visible areas and scene hallucination for occluded regions. VoxFormer proposes a reconstruct-and-densify approach. In the first reconstruction stage, the paper lifts RGB pixels to a pseudo-LiDAR point cloud with monodepth methods, and then voxelize it into initial query proposals. In the second densification stage, these sparse queries are enhanced with image features and use self-attention for label propagation to generate a dense prediction. VoxFormer significantly outperformed MonoScene on SemanticKITTI and is still a single-camera solution. The image feature enhancement architecture heavily borrows the deformable attention idea from BEVFormer.
TPVFormer (CVPR 2023), the first multi-camera attempt
TPVFormer is the first work to generalize 3D semantic occupancy prediction to a multi-camera setup and extends the idea of SOP/SSC from semanticKITTI to NuScenes.
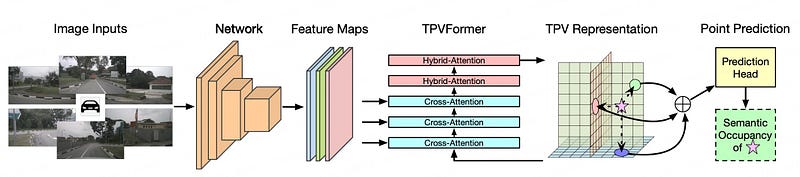
TPVFormer extends the idea of BEV to three orthogonal axes. This allows the modeling of 3D without suppressing any axes and avoids cubic complexity. Concretely TPVFormer proposes two steps of attention to generating TPV features. First, it uses image cross-attention (ICA) to get TPV features. This essentially borrows the idea of BEVFormer and extends to the other two orthogonal directions to form a TriPlane View feature. Then it uses cross-view hybrid attention (CVHA) to enhance each TPV feature by attending to the other two.
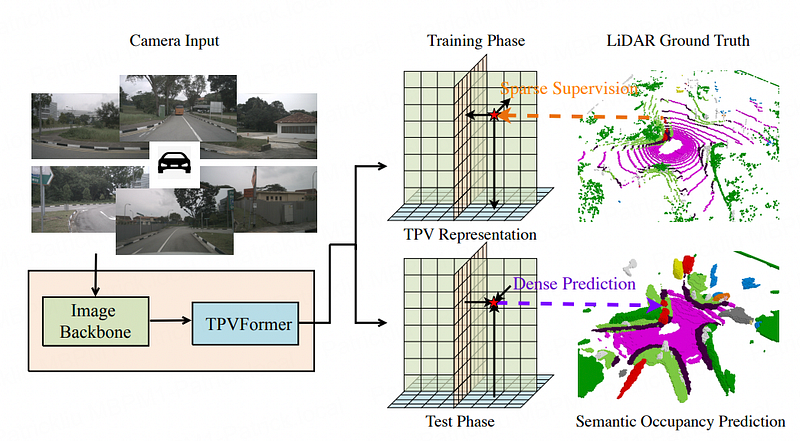
TPVFormer uses supervision from sparse lidar points from the vanilla NuScenes dataset, without any multiframe densification or reconstruction. It claimed that the model can predict denser and more consistent volume occupancy for all voxels at inference time, despite the sparse supervision at training time. However, the denser prediction is still not as dense as compared to later studies such as SurroundOcc which uses densified NuScenes dataset.
SurroundOcc (Arxiv 2023/03) and OpenOccupancy (Arxiv 2023/03), the first attempts at dense label supervision
SurroundOcc argues that dense prediction requires dense labels. The paper successfully demonstrated that denser labels can significantly improve the performance of previous methods, such as TPVFormer, by almost 3x. Its most significant contribution is a pipeline for generating dense occupancy ground truth without the need for costly human annotation.
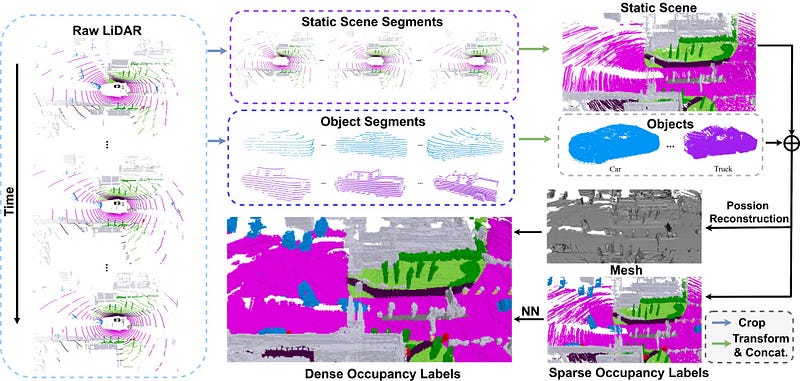
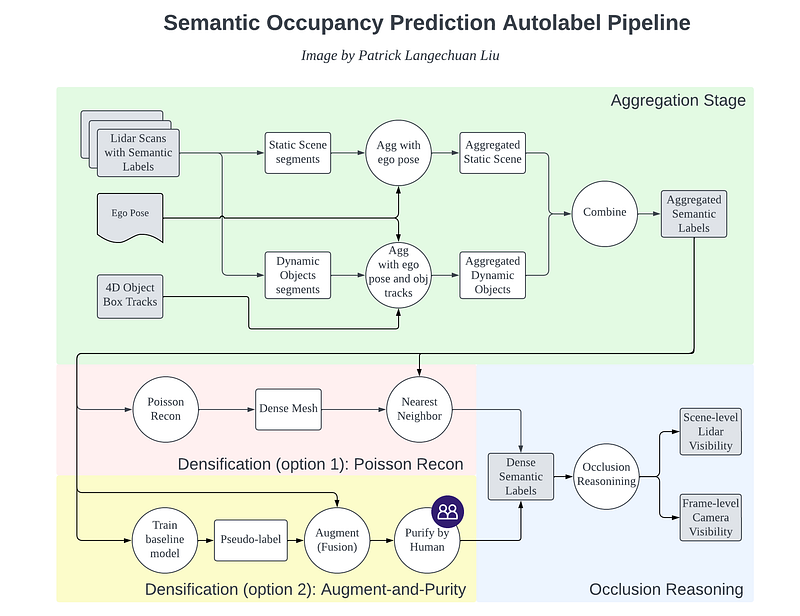
The generation of dense occupancy labels involves two steps: multiframe data aggregation and densification. First, multi-frame lidar points of dynamic objects and static scenes are stitched separately. The accumulated data is denser than a single frame measurement, but it still has many holes and requires further densification. The densification is performed by Poisson Surface Reconstruction of a triangular mesh, and Nearest Neighbor (NN) to propagate the labels to newly filled voxels.
OpenOccupancy is contemporary to and similar in spirit to SurroundOcc. Like SurroundOcc, OpenOccupancy also uses a pipeline that first aggregates multiframe lidar measurements for dynamic objects and static scenes separately. For further densification, instead of Poisson Reconstruction adopted by SurroundOcc, OpenOccupancy uses an Augment-and-Purify (AAP) approach. Concretely, a baseline model is trained with the aggregated raw label, and its prediction result is used to fuse with the original label to generate a denser label (aka “augment”). The denser label is roughly 2x denser, and manually refined by human labelers (aka “purify”). A total of 4000 human hours were invested to refine the label for nuScenes, roughly 4 human hours per 20-second clip.
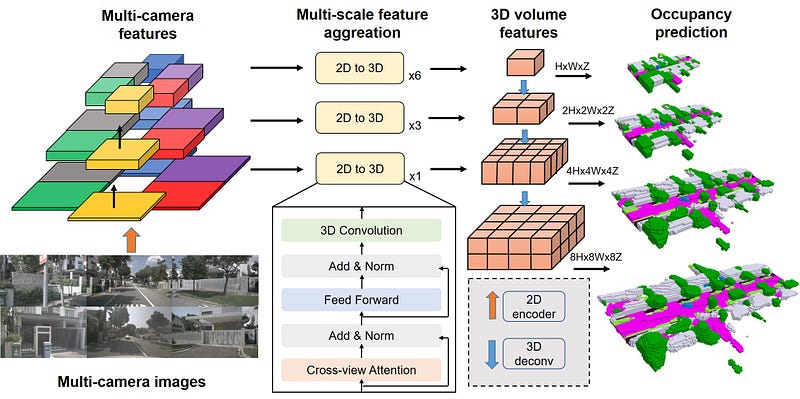
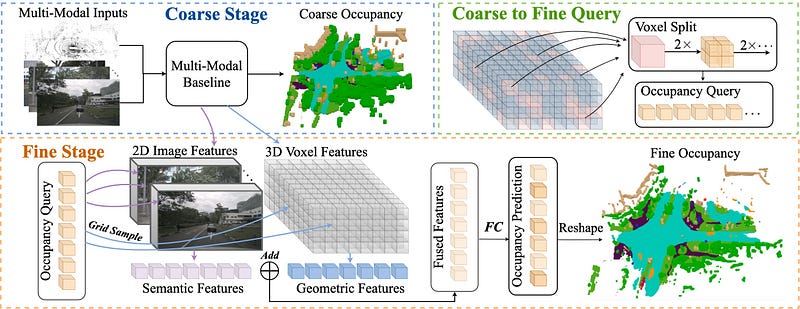
Compared to the contribution in the creation of the dense label generation pipeline, the network architecture of SurroundOcc and OpenOccupancy are not as innovative. SurroundOcc is largely based on BEVFormer, with a coarse-to-fine step to enhance 3D features. OpenOccupancy proposes CONet (cascaded occupancy network) which uses an approach similar to that of Lift-Splat-Shoot to lift 2D features to 3D and then enhances 3D features through a cascaded scheme.
Occ3D (Arxiv 2023/04), the first attempt at occlusion reasoning
Occ3D also proposed a pipeline to generate dense occupancy labels, which includes point cloud aggregation, point labeling, and occlusion handling. It is the first paper that explicitly handles the visibility and occlusion reasoning of the dense label. Visibility and occlusion reasoning are critically important for the onboard deployment of SOP models. Special treatment on occlusion and visibility is necessary during training to avoid false positives from over-hallucination about the unobservable scene.
It is noteworthy that lidar visibility is different from camera visibility. Lidar visibility describes the completeness of the dense label, as some voxels are not observable even after multiframe data aggregation. It is consistent across the whole sequence. Meanwhile, camera visibility focuses on the possibility of detection of onboard sensors without hallucination and differs at each timestamp. Eval is only performed on the “visible” voxels in both the LiDAR and camera views.
In the preparation of dense labels, Occ3D only relies on the multiframe data aggregation and does not have the second densification stage as in SurroundOcc and OpenOccupancy. The authors claimed that for the Waymo dataset, the label is already quite dense without densification. For nuScenes, although the annotation still does have holes after point cloud aggregation, Poisson Reconstruction leads to inaccurate results, therefore no densification step is performed. Maybe the Augment-and-Purify approach by OpenOccupancy is more practical in this setting.
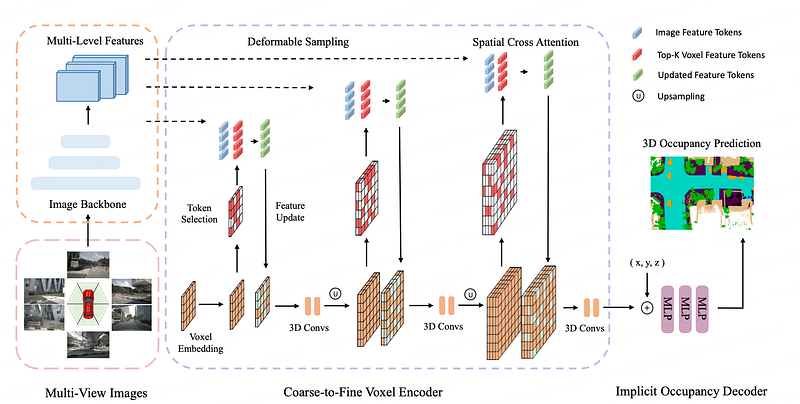
Occ3D also proposed a neural network architecture Coarse-to-Fine Occupancy (CTF-Occ). The coarse-to-fine idea is largely the same as that in OpenOccupancy and SurroundOcc. CTF-Occ proposed incremental token selection to reduce the computation burden. It also proposed an implicit decoder to output the semantic label of any given point, similar to the idea of Occupancy Networks.
Comparisons of Technical Details
The Semantic Occupancy Prediction studies reviewed above are summarized in the following table, in terms of network architecture, training losses, evaluation metrics, and detection range and resolution.
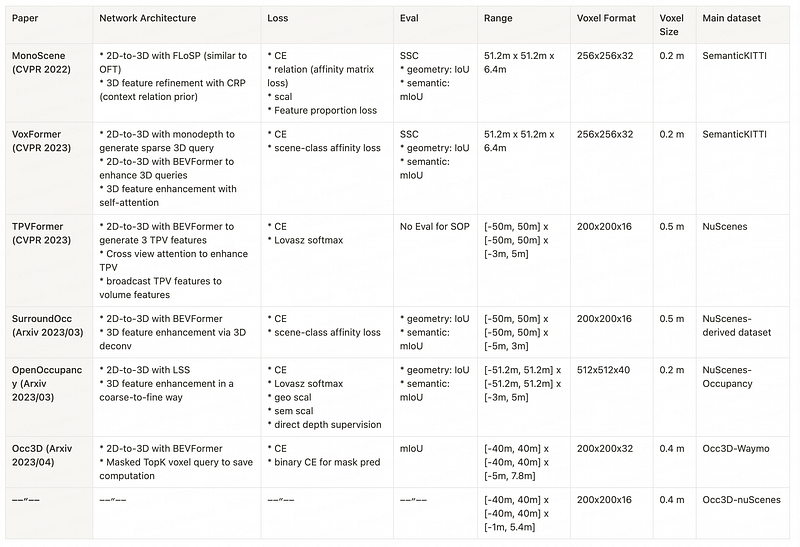
Network Architecture
Most of the studies are based on proven state-of-the-art methods for BEV perception, such as BEVFormer and Lift, Splat, Shoot. The architecture can be largely divided into two stages, 2D-to-3D feature lifting, and 3D feature enhancement. See the above table for a more detailed summary. The architecture seems to have largely converged. What matters most is the dense occupancy annotation generation pipeline, and dense supervision during training.
Below is a summary of the autolabel pipeline to generate dense occupancy labels in SurroundOcc, OpenOccupancy, and Occ3D.
Training Loss
The semantic occupancy prediction task is very similar to semantic segmentation, in that SOP has to predict one semantic label for every voxel in 3D space, while semantic segmentation has to predict one semantic label for every measurement point, be it a pixel per image, or a 3D point per lidar scan. The main loss for semantic segmentation has been cross-entropy loss and Lovasz loss. The Lovasz extension enables direct optimization of the mean intersection-over-union (IoU) metric in neural networks.
Perhaps inspired by Lovasz, monoScene proposed several other losses that can directly optimize evaluation metrics. However, they seem esoteric and not fully supported by ablation studies.
Evaluation Metrics
The primary metric is IoU for geometry occupancy prediction (whether a voxel is occupied) and mIoU (mean IoU) for semantic classification (which class an occupied voxel belongs to). These metrics perhaps would be inadequate for industrial applications.
Vision-based SOP task needs to mature for industrial use and to replace lidar. Although both precision and recall matter as is calculated in the IoU metric, precision is always more important for ADAS (Advanced Driver Assistance Systems) applications to avoid phantom braking, as long as we still have a driver behind the wheel.
Detection Range and Resolution
All current tracks predict 50 meters around the ego vehicle. Voxel resolution varies from 0.2 m for SemanticKITTI to 0.4 m or 0.5 m for NuScenes and Waymo datasets. This is a good starting point, but perhaps still inadequate for industrial applications.
A more reasonable resolution and range may be 0.2 m for the range within 50 m, and 0.4 m for the range between 50 m to 100 m.
Related tasks
There are two related tasks to SOP, Surrounding Depth Maps and Lidar Semantic Segmentation, which we will briefly review below.
Surround depth map prediction task (such as FSM and SurroundDepth) expands monocular depth prediction and leverages the consistency in overlapped camera field-of-view to further improve the performance. It focuses more on the measurement source by giving each pixel in the images a depth value (bottom-up), while SOP focuses more on the application target in the BEV space (top-down). The same analogy is between Lift-Splat-Shoot and BEVFormer for BEV perception, where the former is a bottom-up approach and the latter is top-down.
Lidar Semantic Segmentation focuses on assigning each lidar point cloud in a lidar scan a semantic class label. Real-world sensing in 3D is inherently sparse and incomplete. For holistic semantic understanding, it is insufficient to solely parse the sparse measurements while ignoring the unobserved scene structures.
Takeaways
- The neural network architecture in semantic occupancy prediction seems to have largely converged. What matters the most is the autolabel pipeline to generate dense occupancy labels and dense supervision during training.
- The current detection range and voxel resolution adopted by common datasets would be inadequate for industrial applications. We need more detection range (e.g., 100 m) at a finer resolution (e.g., 0.2 m).
- The current evaluation metrics would be inadequate for industrial applications as well. Precision is more important than recall for ADAS applications to avoid frequent phantom braking.
- Future directions of semantic occupancy prediction may include scene flow estimation. This will help the prediction of future trajectories of unknown obstacles and collision avoidance during trajectory planning for the ego vehicle.
Note: All images in this blog post are either created by the author, or from academic papers publicly available. See captions for details.
Reference
- SSCNet: Semantic Scene Completion from a Single Depth Image, CVPR 2017
- SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences, ICCV 2019
- MonoScene: Monocular 3D Semantic Scene Completion, CVPR 2022
- VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion, CVPR 2023
- TPVFormer: Tri-Perspective View for Vision-Based 3D Semantic Occupancy Prediction, CVPR 2023
- Occ3D: A Large-Scale 3D Occupancy Prediction Benchmark for Autonomous Driving, Arxiv 2023/04
- SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving, Arxiv 2023/03
- OpenOccupancy: A Large Scale Benchmark for Surrounding Semantic Occupancy Perception, Arxiv 2023/03
- SimpleOccupancy: A Simple Attempt for 3D Occupancy Estimation in Autonomous Driving, Arxiv 2023/03
- OccFormer: Dual-path Transformer for Vision-based 3D Semantic Occupancy Prediction, Arxiv 2023/04
- BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers, ECCV 2022
- FSM: Full Surround Monodepth from Multiple Cameras, ICRA 2021
- SurroundDepth: Entangling Surrounding Views for Self-Supervised Multi-Camera Depth Estimation, CoRL 2022
- Lift, Splat, Shoot (LSS): Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D, ECCV 2020
- OFT: Orthographic Feature Transform for Monocular 3D Object Detection, BMVC 2019





