
How I made $150 in 5 minute Data Matching w/ Python
A simple Python Script using RapidFuzz
I have a very good repeat customer who needs a job done every few months or so. His gigs almost always pay around $150 but they are quite easy to perform with a Python as you will see in this article. It only took me around 5 minutes to write the code for this gig. It will actually take me longer than that to write this article. The code itself will take some hours to run but I will let it run while I sleep.
Actual runtime for the code was 5 hours 40 minutes and 57 seconds.

TIP
Use rapidfuzz because it performs much better than fuzzwuzzy. To learn more read my other article on rapidfuzz.
The Problem
The customer sent me two lists. The second list is much longer than the first list. The first list contains a list of companies and so does the second list. However, the second list contains almost 120,000 names more than the first list. He is looking for companies with similar names in the second list to the first list. For example, the first list might have ‘ABC Company’ and the second list might have ‘ABC Company LLC’. These are the matches that he needs.
My Approach
So, the first step to complete this gig is to load pandas and rapidfuzz.
import pandas as pd
from rapidfuzz import fuzzThe next step is to load the two lists:
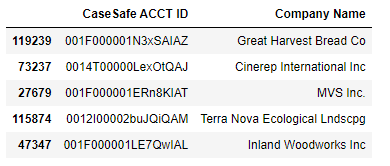
df = pd.read_excel('CompanyNamesLookup.xlsx', sheet_name = 'List 1')
ef = pd.read_excel('CompanyNamesLookup.xlsx', sheet_name = 'List 2')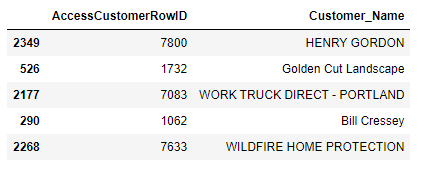
Then, I just needed to loop through the first list as the outer loop, and then the loop through the second list as the inner loop. Perhaps, there was a faster way to get this done but since this will work while I sleep, I really don’t care.
I want all matches that give me a fuzz ratio of 90.0 or more. Fuzz.ratio first compares the customer_name in list 1 to each company name in list 2. If the score is greater than to equal to 90, then the score along with the Account ID is appended to matches. After each cycle matches is added to the dataframe in List 1. Then, I repeat, each time I must re-initialize matches.
%%timedf['Match'] = ''for index, row in df.iterrows():
matches = []
for i, r in ef.iterrows():
score = fuzz.ratio(row['Customer_Name'], r['Company Name'])
if score >= 90:
matches.append([r['Company Name'], r['CaseSafe ACCT ID']])
df.at[index, 'Match'] = matches
if matches:
print(index, row['Customer_Name'], ': ', matches)Here is a screenshot of the code for a better view:

More content at PlainEnglish.io. Sign up for our free weekly newsletter. Follow us on Twitter, LinkedIn, YouTube, and Discord.