
$150 (1 hour) to Parse Addresses with Python
I recently answered an ad on Craigslist from an accounting firm that had about 2500 addresses that needed parsing. Of course, python was the tool that came immediately to mind. After a little research, I found that the pandas_usaddress was the perfect package to handle this particular gig.
The customer provided the list in Excel and I offered to parse them for $100 — thinking that it would take about an hour as I knew that I would have to clean up a few manually. When I completed the job the customer agreed to pay $150 and also took my information for future jobs — so hopefully this will be a long-term relationship.
So, to get this done, I imported this package:
import pandas as pd
import pandas_usaddress as pdadf = pd.read_csv(filename)I then used the pda package to parse the address as follows:
dfa = pda.tag(df, ['Address'], granularity='low', standardize=True)
dfa.head()The package produced output as such:
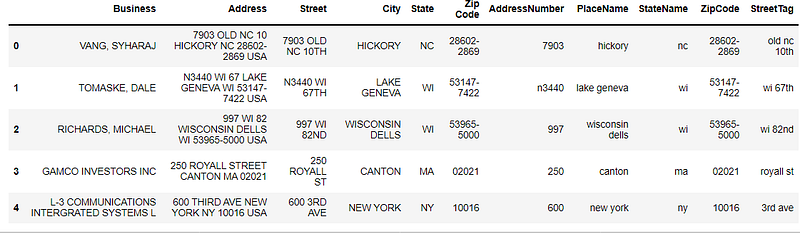
Finally, I added a little code to join the address so I could produce results in the way that my client wanted.
for index, row in dfa.iterrows():
df.at[index, 'Street'] = (str(row['AddressNumber']) + ' ' + str(row['StreetTag'])).upper()
df.at[index, 'City'] = str(row['PlaceName']).upper()
df.at[index, 'State'] = str(row['StateName']).upper()
try:
df.at[index, 'Zip Code'] = str(row['Address']).split(str(row['StateName']).upper())[1].split()[0]
except:
print(row['Address'])
passHere is a picture of the code to make it a little clearer:

Then, I eliminated the extra columns:
dfb = dfa[['Business', 'Street', 'City', 'Zip Code']].copy()
dfb.head()To produce the following result:
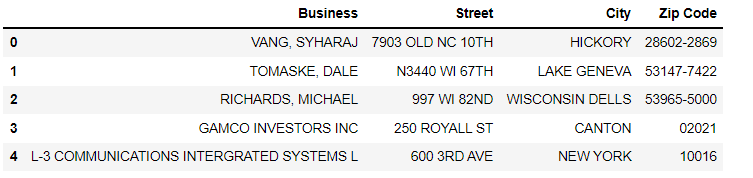
More content at PlainEnglish.io. Sign up for our free weekly newsletter. Follow us on Twitter and LinkedIn. Check out our Community Discord and join our Talent Collective.