
{kind=link}
11 ML Algorithms You Should Know
Important Machine Learning algorithms in 2021

Of course, there is a lot of advancement that happened all over the years in the field of data science. Some new efficient algorithms have been proposed as well through different research works. But few basics will remain the fundamentals of all advanced algorithms.
Below is the list of such 11 ML algorithms which have been mostly used in a data science field and asked in Data science interviews as well.
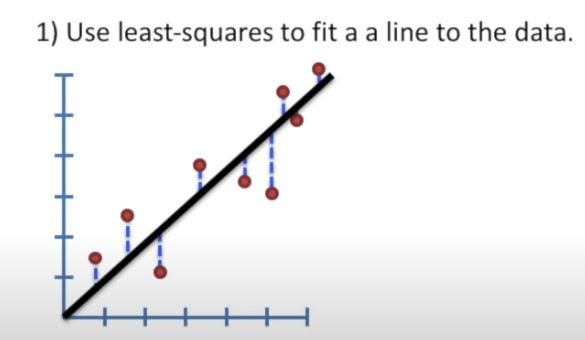
- Linear Regression:- It is the most well-known and well-understood algorithm in statistics and machine learning. Linear regression is a linear model, e.g., a model that assumes a linear relationship between the input variables (x) and the single output variable (y) which means y can be easily computed using the linear relationship.
- When there is a single input variable(x), the equation is referred to as simple linear regression.
- When there is more than one input variable, the equation is referred to as multiple linear regression.
The Equation: y = B0 + B1*x (where x is input variable, y is the output variable and B0 and B1 are the coefficients)
The line of best fit is found by minimizing the squared distances between the points and the line of best fit and this is known as minimizing the sum of squared residuals.
A residual is simply equal to the predicted value minus the actual value.
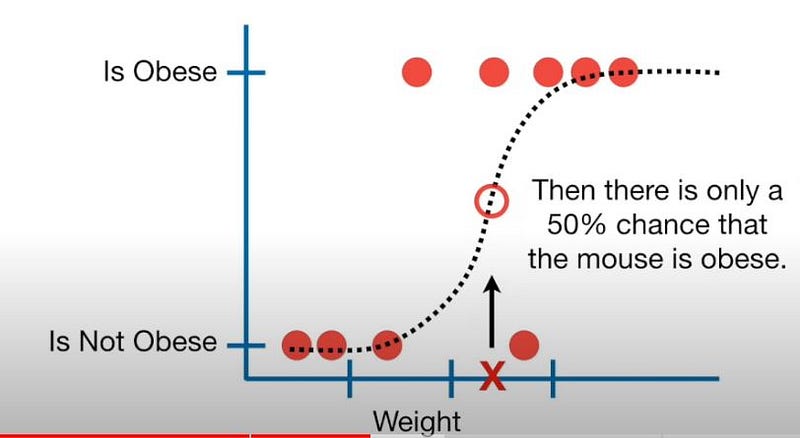
2. Logistic Regression:- Logistic regression is a classification algorithm based on the function which is used at the core of the method, logistic function or sigmoid function. It’s an S-shaped curve that is used to predict a binary outcome (1/0, Yes/No, True/False) given a set of independent variables.
- It can also be thought of as a special case of linear regression when the outcome variable is categorical, where we are using the log of odds as a dependent variable.
- It predicts the probability of occurrence of an event by fitting data to a logit function.
p(X) = e^(b0 + b1*X) / (1 + e^(b0 + b1*X))
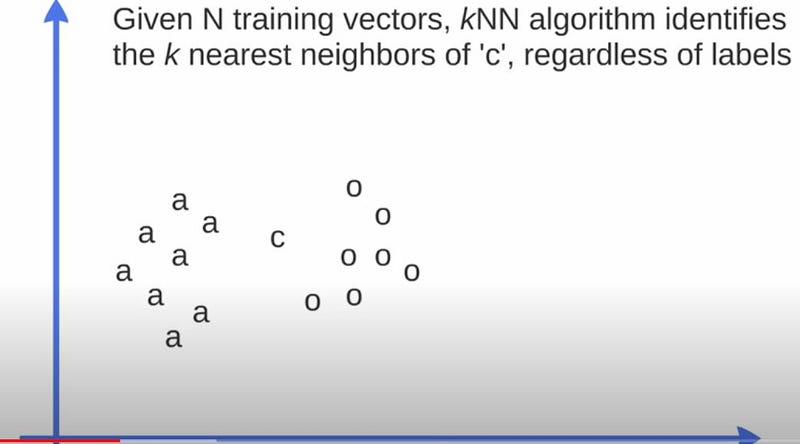
3. K-Nearest Neighbours:- K-nearest neighbors (KNN) algorithm is a supervised machine learning algorithm that can be used to solve both classification and regression problems.
- It works by finding the distances between the new data point added and the points already existed in the two separate classes. Whatever class got the highest votes, the new data point belongs to that class.
EuclideanDistance(x, xi) = sqrt( sum( (xj — xij)² ) )
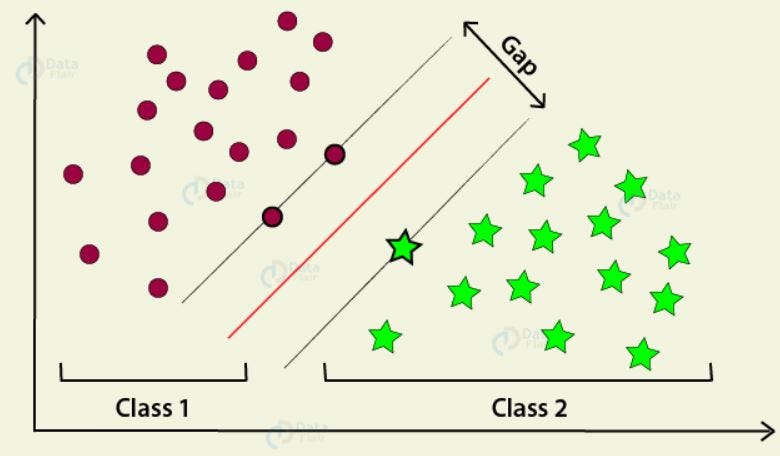
4. Support Vector Machines:- It is a supervised machine learning algorithm that also can be used for both tasks:- classification as well as regression. however, It is mostly used in classification problems.
- An SVM will find a hyperplane or a boundary between the two classes of data that maximizes. There are other planes as well which can separate the two classes, but only the SVM hyperplane can maximize the margin between the classes.
B0 + (B1 * X1) + (B2 * X2) = 0 where, B1 and B2 determines the slope of the line and B0 (intercept) found by the learning algorithm. X1 and X2 are the two input variables.
5. Decision Trees:- Decision tree algorithms are referred to as CART or Classification and Regression Trees. It is a flowchart like a tree structure, where each internal node denotes a test on an attribute, each branch represents an outcome of the test, and each leaf node (terminal node) holds a class label.
- A Gini score gives an idea of how good a split is by how mixed the response classes are in the groups created by the split.
6. Random Forest:- Random Forests are an ensemble learning technique that builds off of decision trees.
- Random forests involve creating multiple decision trees using bootstrapped datasets of the original data and randomly selecting a subset of variables at each step of the decision tree.
- The model then selects the mode of all of the predictions of each decision tree (bagging).
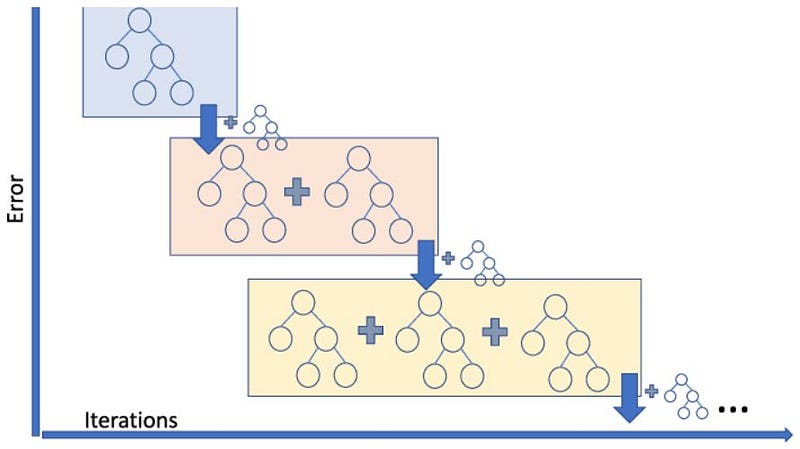
7. AdaBoost:- Adaptive boost is also an ensemble algorithm that leverages bagging and boosting methods to develop an enhanced predictor.
- AdaBoost creates a forest of stumps rather than trees. A stump is a tree that is made of only one node and two leaves.
- AdaBoost takes a more iterative approach in the sense that it seeks to iteratively improve from the mistakes that the previous stump(s) made.
8. Gradient Boost:- Gradient Boost is also an ensemble algorithm that uses boosting methods to develop an enhanced predictor.
- Unlike AdaBoost which builds stumps, Gradient Boost builds trees with usually 8–32 leaves.
- Gradient Boost views the boosting problem as an optimization problem, where it uses a loss function and tries to minimize the error. This is why it’s called Gradient boost, as it’s inspired by gradient descent.
9. XG Boost:- XGBoost is one of the most popular and widely used algorithms today because it is simply so powerful.
- It is similar to Gradient Boost but has a few extra features that make it that much stronger.
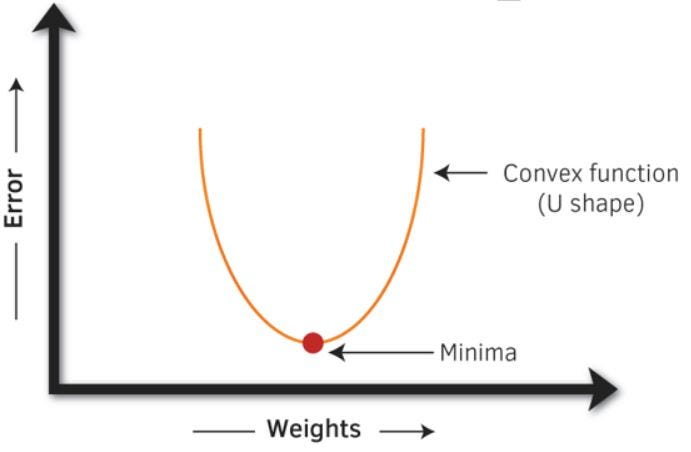
- Newton Boosting — Provides a direct route to the minima than gradient descent, making it much faster.
- An extra randomization parameter — reduces the correlation between trees, ultimately improving the strength of the ensemble.
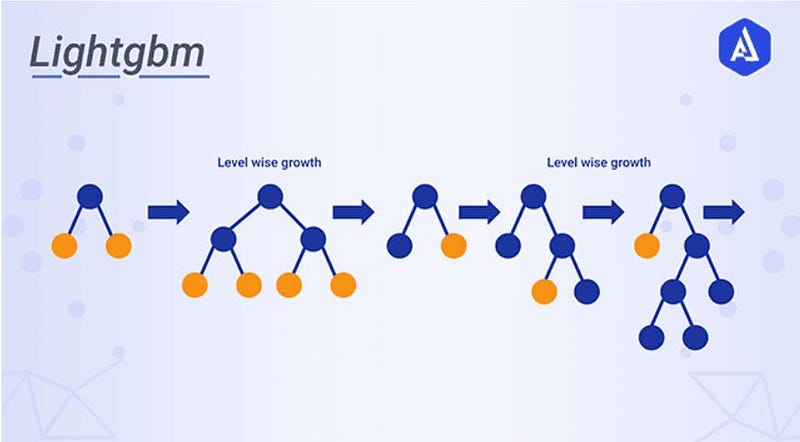
10. Light GBM:- It is another type of boosting algorithm that has shown to be faster and sometimes more accurate than XGBoost.
- It uses a unique technique called Gradient-based One-side sampling (GOSS) to filter out the data instances to find a split value.
11. Naive Bayes:- It is a classification algorithm used for binary (two-class) and multiclass classification problems. It is used when the output variable is discrete.
- As the name specifies, this algorithm is entirely based on Bayes's theorem. Bayes’ theorem says we can calculate the probability of a piece of data belonging to a given class if prior knowledge is given.
- P(class|data) = (P(data|class) * P(class)) / P(data)
Please let me know in the comment section if I have forgotten any other important ML algorithm. Thanks for reading.
So, if any of my blog posts have been of help to you, and you feel generous at the moment, don’t hesitate to buy me a coffee. ☕😍

Yes, click me.
And yes, buying me a coffee (and lots of it if you are feeling extra generous) goes a long way in ensuring that I keep producing content every day in the years to come.You can reach me via the following :
- Subscribe to my YouTube channel for video content coming soon here
- Follow me on Medium
- Connect and reach me on LinkedIn
- Become a member:- https://techykajal.medium.com/membership
Check out my other Blogs as well: