
10x times faster Pandas Apply in a single line change of code
Speed-up Pandas processing workflow with Swifter Package
Pandas is one of the popular Python packages among the data science community, as it offers a vast API and flexible data structures for data explorations and visualization. When it comes to handling and processing large-size datasets, it fails.
One can load and process a large-size dataset in chunks or use distributed parallel-computing libraries like Dask, Pandarallel, Vaex, etc. Modin library or multiprocessing package can be used to execute the Python functions in parallel and speed up the workflow. In my previous articles, I have discussed the hands-on implementation of Dask, Vaex, Modin, multiprocessing libraries.
Sometimes we are not willing to use Dask or Vaex library instead of Pandas, or one does not want to write all that extraneous code just to execute few functions in parallel.
Can we parallelize the execution of the Python function without much code change? —Yes for sure
apply() function in Pandas library allows developers to pass a function and apply it on every single value of the series. The function's execution apply() comes with a huge improvement as it segregates the data according to the conditions required.
Usage of apply() function is preferred for Pandas Series rather than the custom calling of the function. In this article, we will discuss how to further parallelize the execution of the apply() function and optimize the time constraints using the Swifter package.
Swifter:
Swifter is an open-source package that speeds up the function execution. It can be integrated with Pandas objects for ease of usage. The parallel execution of any function in Python can be done with a single line change of code by integrating the swifter package.
How does it work?
Swifter automatically picks the best way to implement the apply() function by either vectorizing or using Dask implementation in the backend to parallelize the execution. For a small size dataset Swifter may choose to execute with Pandas apply() function.
Installation:
The swifter package can be installed from PyPl using pip install swifter and import it using import swifter.
Implementation and Usage:
I have created a function that performs some random operations on the Pandas Series. Firstly, we will execute the function using apply():
# Call random_function for col1 and col2 columns using apply()df['new_col'] = df.apply(lambda x: random_func(x['col1'], x['col2']))Now to parallelize the function execution we can integrate the swifter package with Pandas data frame object:
# Call random_function for col1 and col2 columns for parallel executiondf['new_col'] = df.swifter.apply(lambda x: random_func(x['col1'], x['col2']))Just by integrating the keyword swifter, one can parallelize the execution of the function.
Benchmarking:
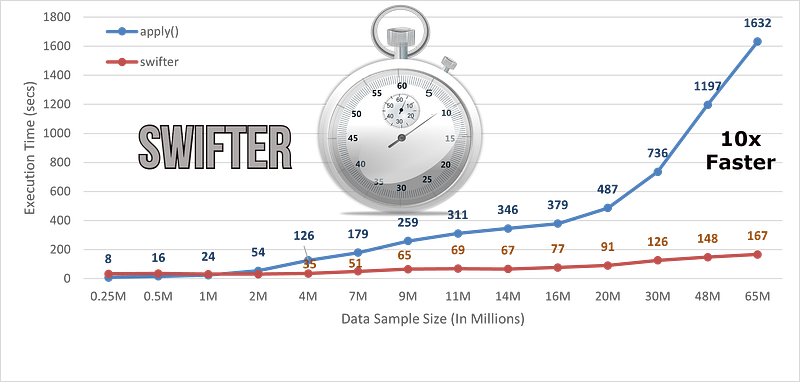
I have compared the benchmark time numbers for the execution of the function using apply() and by integrating the swifter package with Pandas data frame object then calling apply(). Now let's observe the improvements in the execution speed.
The performance is recorded on a system with RAM: 64GB with 10 CPU cores.
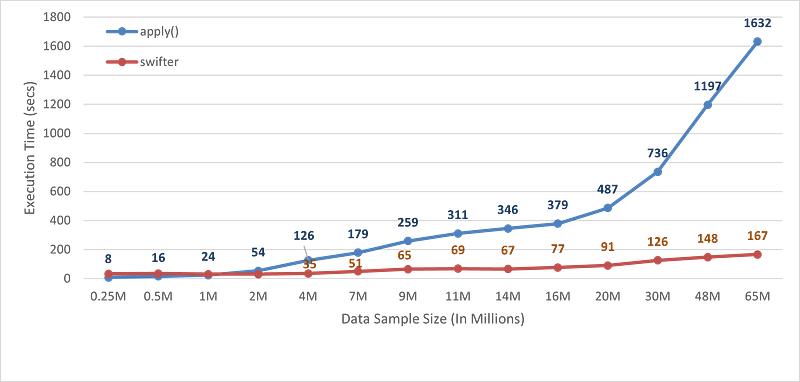
We can observe from the above plot that after using the swifter package for parallelism, speed-up the workflow by almost 10x times for 65 million data samples.
Conclusion:
Swifter is a great tool to parallelize the execution of your Python function. It automatically chooses the fastest way to execute your function by either vectorizing or using Dask in the backend.
We are getting a 10x faster execution time for 65 million records, which will increase further as sample size increases.
It can be a handy tool to optimize the function execution with just one work of code change. One can also use the Python multiprocessing library to execute your custom in parallel, but it will require few lines of change in the code.
Read my previous article related to parallelization of optimization of the code:
- 4 Libraries that can parallelize the existing Pandas ecosystem
- Speed up your Pandas Workflow with Modin
- 30 times Faster Python Function Execution with Multiprocessing module
- 400x times faster Pandas Data Frame Iteration
- 3x times faster Pandas with PyPolars
- Optimize Pandas Memory Usage for Large Datasets
- 20x times faster Grid Search Cross-Validation
References:
[1] Swifter GitHub Repository: https://github.com/jmcarpenter2/swifter
Thank You for Reading





