
The evolution of data scientists
10 trends that will shape the role of data scientists in the next 10 years
Will we see the rise of prompt engineers?
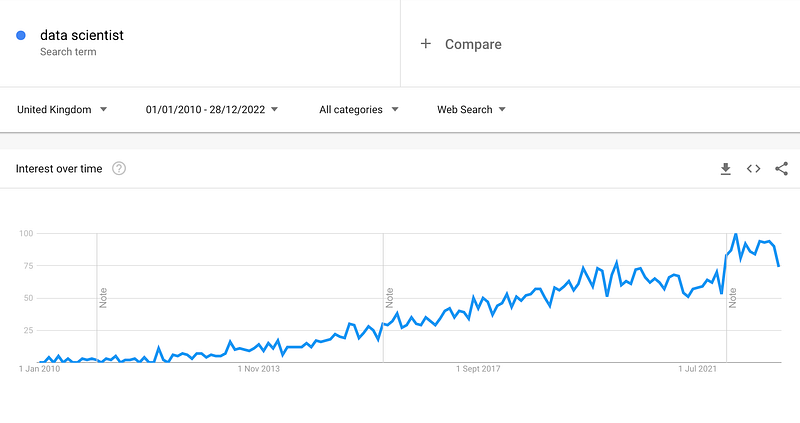
The data scientist role has exploded in popularity over the past decade as organisations have increasingly turned to data-driven decision making to stay competitive (see Google trends chart below on the “data scientist” search term). In this short time, the role has evolved significantly, and the next decade will undoubtedly bring even more change.
In 10 years, the role of a data scientist may well bear very little resemblance to our current expectations, especially as new technologies and approaches continue to emerge. It is therefore important for data scientists to keep themselves abreast of the latest developments in this space and adapt as needed in order to remain competitive in this increasingly crowded market.
A brief history…
The role of a data scientist has evolved significantly over time, with roots dating back to over 50 years ago with the development of the field of statistics. The first mention of the concept of machine learning, which is core to the recent evolution (or arguably revolution) of the data science field, was actually published in 1943 by logician Walter Pitts and neuroscientist Warren McCulloch, and the term “data science” was coined in 1974 by Peter Naur.
However, it was only in the early 2010s where the field started to take off at an astronomical pace. There are a few factors that have contributed to this exponential growth:
- Exponential proliferation of data: 95+% of all data has been created in the past 10 years — source: Statistica
- Ongoing advancement of technology: Today’s smartphones are almost a thousand times faster than the mid-’80s Cray-2 Supercomputer, and several multiples faster than the computer onboard NASA’s Perseverence Rover currently exploring Mars — Source: Samsung
- Increased sophistication of learning algorithms/architectures: e.g. New transformer-based deep learning architectures that have powered the latest generation of human-like natural language processing capabilities such as ChatGPT
- Increasing importance of data-driven decision making: Companies like Alphabet (Google) and Amazon have built arguably the biggest and most successful companies by putting data at the heart of their business model
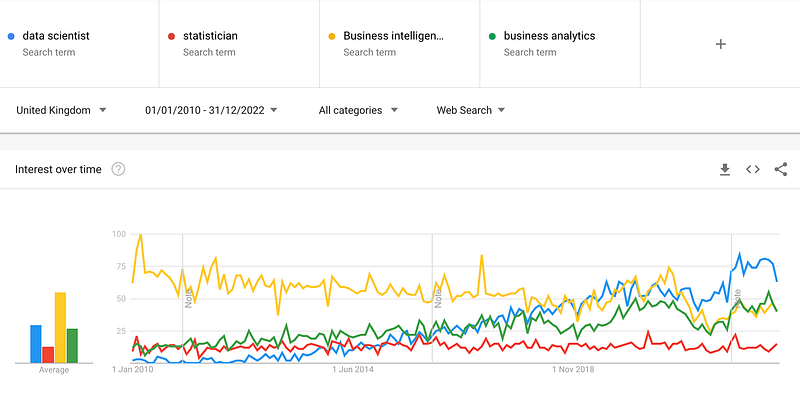
Up until as recently as 5–6 years ago, related titles and terms such as Statistician, Business Intelligence and Business Analytics were more widely used in the industry compared to data scientist (see the Google Trends chart below comparing the 4 terms and the increasing popularity of the data scientist term). It is therefore normal to expect this relatively new role to continue evolving in the next 10 years.
The 10 trends shaping the next 10 years…
Here are 10 trends that are likely to shape the future of the data science field and its related roles in the next 10 years (in no particular order):
- Auto-ML: Auto-ML, or automated machine learning platforms, are becoming increasingly prevalent and automating more and more of the data science lifecycle, from sourcing data and engineering features, to running machine learning experiments, evaluating and selecting the best models, and deploying them to production. This will allow data scientists to work more efficiently (i.e. fail and eventually succeed faster) and focus more on the interpretation of results and the development of insights. Solutions like DataRobot are already well on their way to support this vision of the future.
- MLOps: MLOps, or machine learning operations, is a set of practices and tools that are used to manage the production lifecycle of machine learning models, e.g. auto-retraining, dynamic learning, packaging and containerising, and releasing of models to production. As MLOps practices become more efficient and effective, it will free up data scientists’ time away from mundane deployment activities and retraining or calibrating existing models.
- Large language models: Large language models, such as BERT and GPT-3, are expected to become more widely used as base layers for many machine learning models. This allows data scientists to use transfer learning to fine-tune and apply these models to their specific problem rather than needing to build and train such models from scratch. This trend will likely result in only a few larger companies hiring superstar data scientists and researchers supported by heavy compute power (e.g. 1000s of GPUs/TPUs) to train these large base models, while others would “only” apply or retrain these models to solve their specific problems.
- Generative AI and the eventual rise of Prompt Engineers: As generative AI systems continue to advance, there will be an increasing importance on “prompt engineering,” which involves using natural language prompts to generate outputs from AI/ML models. With the recent roll-out of the likes of ChatGPT and DALLE-2 from OpenAI, we’re already seeing the importance of what a difference a good prompt can make in getting the best out of these AI systems. Just like Search Engine Optimization (SEO) has become the key battleground in today’s world of search engines which led to the rise of SEO specialists, I expect there to be a new crop of Prompt Engineering Optimization specialists (PEO instead of SEO) to help people get the most out of this new breed of generative AI systems. (See this blog from OpenAI on the topic of prompt engineering!)
- Domain knowledge increasingly important to give edge: As the “art” of data science becomes more mainstream and automated, domain knowledge will become increasingly important to give data scientists an edge. This means that data scientists will need to develop a deep understanding of the industries and sectors in which they operate, as well as a strong grasp of the business and organizational context in which data is being used. This is already the case for example for “quants” within financial services, who are a specialised breed of data scientists with specific expertise in financial engineering and financial/risk modelling in addition to having strong data science skills.
- Prominence of Low/no-code solutions: Low/no-code solutions are likely to become more prominent in the data science field. This will allow data scientists to work more efficiently and focus more on solving problems and interpreting results, rather than on coding itself. Solutions such as Dataiku DSS, Azure ML Studio and Amazon Sage are already providing such powerful low/no-code solutions for data scientists and other data related roles. Writing high quality code will no longer be a competitive battleground for data scientists, especially as systems such as ChatGPT are already capable of producing excellent code snippets using simple prompts. The strongest data scientists will be those who are best at understanding and formulating their problems and designing/architecting the right solutions rather than spending their time debugging and optimizing code. It will also allow more brain power to go analysing outputs and identifying actionable insights.
- Big(ger) Data: New technologies leveraging high performance distributed computing such as Spark and Hadoop have recently come to light to deal with the stupendous amount of data that we continue to generate on a daily basis (a.k.a Big Data). The steepness of this exponential growth will only increase over the next 10 years and there will need to be a new generation of technologies to deal with this even “Bigger Data”. Increased Interoperability will also be an important feature in these solutions that would allow data scientists of the future to seamlessly tap into 100s of different sources of data, and combine and transform 100s of terabytes of data in seconds.
- Explainable & Ethical AI: A lot of the trends that are highlighted here are on the one hand enabling increasingly complex use-cases, and on the other hand freeing up data scientists to focus more on interpreting results and generating insights. A natural byproduct of this juxtaposition is the need to create better explainability techniques that help data scientists open up and understand the so-called “black-box” that such complex models bring about. Data scientists will also likely have increasing ethical responsibilities to control the ‘behaviour” of their AI systems. A good real example is the safety policies that OpenAI has built in to ChatGPT that avoid answering certain types of questions that they consider harmful. Some of these responsibilities may well be more rigidly enforced by regulators/governments in the coming years given the immense impact that such solutions can have on our lives. One of the most effective ways to manage and control the behaviour of AI systems is also to truly understand and explain their outputs and inner workings, which reinforces the importance of “Explainable AI”.
- Cloud: The use of cloud computing is likely to continue growing in the data science field, as it provides virtually limitless compute power that is both easily accessible and inexpensive. Such cloud solutions will continue to become even more seamlessly accessible to data scientists, who would no longer need large infrastructure engineering teams or their own infrastructure to maintain, and would be able to spin-up their environment within a few clicks and scale up and down as they wish.
- Productization of everything: We are already living in the era of productization. I highlighted some examples of existing digital products for several of the listed trends (e.g. DataRobot, Amazon SageMaker, Azure cloud, ChatGPT, etc.) and more and more similar products operating in this space will invariably keep popping up. However, another aspect of productization that will impact data scientists is the concept of data products that are becoming increasingly popular with the introduction of the Data Mesh concept by Zhamak Dehghani, who introduces this new data architecture paradigm for enterprises, along with a number of principles, including the shift from data as an asset to data as a product. As more firms embrace these principles, data will become much more easily accessible for data scientists, who would in turn spend less of their time looking for data and finding ways to source them, and instead simply search for their required data products on easy-to-navigate marketplaces and connect to them via standardised APIs or other means within just a few clicks.

The dotAI versus the dotcom bubble
There are many similarities between the dotcom internet bubble and the current state of affairs in the AI space. Back in the 1990s, simply having a website was seen as a differentiator for companies. It created this bubble, which was eventually burst in early 2000s, but the importance of website has continued to increase and has very much shaped our current lives. Flash forward 20-odd years to now, where creating a website is not only free but can literally be done in a matter of clicks within a few minutes using platforms such as Wix and Wordpress.
There is a similar trend with AI, whereby in the last few years many companies suddenly became dotAI (or .ai) companies, which massively increased their valuation and investor attractiveness. This has resulted in a bubble in the valuation of AI companies, which I believe is yet to fully burst. That said, given the widespread educational content on the subject of data science, investors are becoming more savvy in weeding out the companies who truly use AI as a differentiating value generator, versus those who simply incorporate it in their business for its namesake.
Regardless of when or if the AI bubble bursts, in 10 years, similar to websites, we will be able to create AI models freely in a matter of minutes, with just a few clicks and keystrokes. Therefore, just as the current battleground on the internet is no longer about who can create the best websites but about the value that a website creates for its users, the battleground for AI will no longer be about who can create AI models but about finding those applications of AI that solve valuable problems that people and organisations would be willing to use and pay for.
In conclusion…
The future of data science is already here. Large generative language models like ChatGPT allow data scientists to write code using simple prompts, while libraries like auto-sklearn and auto-keras enable the building of ML pipelines using Auto-ML. Low/no code solutions like DataRobot and Dataiku even enable the development of full end-to-end ML solutions with only a few lines of code. The pace and breadth of adoption of these solutions will continue to increase in the coming years, and they will replace and augment more and more of data scientists’ role. In other words, the role of a data scientist as we know it today will evolve significantly over the next decade.
We may also see the emergence of new roles in the data science field. I already mentioned the rise of Prompt Engineers but another role closer to home could be what I would call “data science architect”; a new breed of data scientist who would no longer write code or run hundreds of experiments to find the right features, algorithms, and hyper-parameters; Instead they would focus on framing problems, identifying appropriate products, designing/architecting end-to-end solutions, and integrating the various components together to able to deploy ML solutions.
Perhaps in 10 years we would be able to write such a prompt on ChatGPT 10.0, and sit back and enjoy life!
“Find a problem in the area of sustainability that can be solved using a machine learning based solution; write the code for that solution; deploy it on my Azure subscription; define a pricing strategy to make profit; create a website and other appropriate marketing channels to market it; include some code that assesses customer engagement with the solution and continuously improve it based on customer feedback. Send me a report of the financials on a monthly basis.” — The ultimate prompt by author