
8 Tips and Tricks for Working with Large Datasets in Machine Learning
Essential guide to memory and code optimization

Pandas and Scikit-learn are popular libraries among the data science community, as they come with high performance, and easy-to-use data structures and functions. Pandas provide data analytics tools for data preparation and analysis. These libraries work well working with the in-memory datasets (data that fits into RAM), but when it comes to handling large-size datasets or out-of-memory datasets, it fails and may cause memory issues.
In this article, I will discuss 10 such tips and tricks that one can use while working with a large-size dataset. These tricks will help them to avoid memory overflow issues while working with out-of-memory or large datasets and also speed up their workflow.
Checklist:
1) Read dataset in chunks with Pandas
2) Optimize the datatype constraints
3) Prefer Vectorization
4) Multiprocessing of Functions
5) Incremental Learning
6) Warm Start
7) Distributed Libraries
8) Save objects as Pickle file1.) Read Data in Chunks with Pandas:
Pandas provide API to read CSV, txt, excel, pickle, and other file formats in a single line of Python code. It loads the entire data into the RAM memory at once and may cause memory issues while working with out-of-memory datasets.
The idea is to read/load and process the large dataset in chunks or small samples of datasets.
The above code sample reads the large dataset in chunks (line 14) and performs processing for each of the chunks (line 15) and further saves the processed chunk of data (line 17).
2.) Optimize the Datatype Constraints:
Pandas assign default datatypes to each feature of the dataset by observing the feature values. For features with integral values are assigned int64 datatype and features with decimal values are assigned float64 data type. Find the list below the default list of datatype assigned to each of the features.
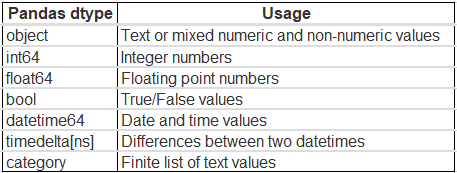
The int64 values range between -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807. For most of the dataset, the integral feature values do not exceed that limit. The idea is to downgrade the feature datatype by observing the maximum and minimum feature values.
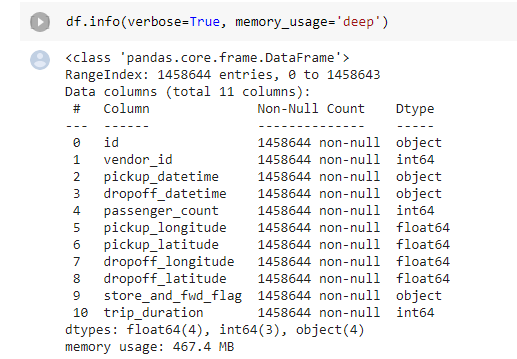
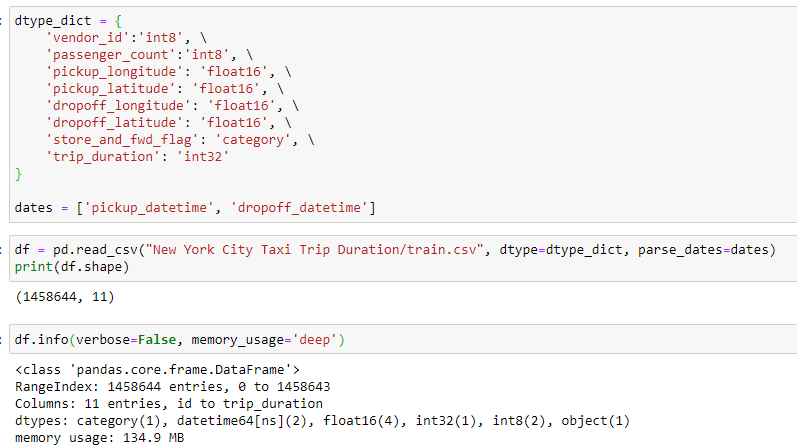
The sample dataset was taking 467.4 MB of memory with the default set of datatype constraints. After typecasting the datatypes the memory usage reduced by ~70% to 134.9 MB.
Read one of my previous articles to get a better understanding of datatype downgrading by typecasting.
3.) Prefer Vectorization for Iteration:
For data processing tasks, one always encounters various situations where it requires to iterate through the dataset. Pandas provide various functions to loop their the instances using iterrows(), itertuples(), iteritems(), where iterrows() being the slowest.
Vectorization of features speeds up the iteration process. iterrows() iterates through the Pandas Series, and hence being the slowest. itertuples() iterates through the list of tuples and hence comparatively faster.
Follow one of my previous articles, to know more about how to make Pandas iteration 400x times faster.
400x times faster Pandas Data Frame Iteration
Avoid using iterrows() function
towardsdatascience.com
4.) Multiprocessing:
Python is comparatively slower compared to other programming languages as the code is interpreted at runtime instead of being compiled to native code at compile time. Execution of functions for data preprocessing is comparatively slower even after vectorizing the feature vectors.
The idea is to utilize all the cores of the CPU and scale up the computations across all the cores to speed up the workflow. Python comes up with a multiprocessing module, that allows such functionalities.
Follow one of my previous articles, on how to scale Python functions using a multiprocessing module.
5.) Incremental Learning:
Scikit-learn provides an efficient implementation of various classification, regression, and clustering machine learning algorithms. For machine learning tasks where a new batch of learning data comes with time, and re-training the model is not time efficient. Also for out-of-memory datasets, training the entire dataset at once is not feasible, as it’s not possible to load the entire data into the RAM at once
Incremental learning can be employed for such tasks, where the past learning of the model will be restored and the same model will be trained with the new batch of data. Scikit-learn provides
6.) Warm Start:
Scikit-learn comes up with the API warm_start to reuse the aspects of the model learned from the previous parameter value. When warm_start is true then the assigned model hyperparameters are used to fit the model. For example, warm_state can be used to increase the number of trees (n_estimators) in a Random Forest Model. While working with the warm_start parameter, the hyperparameter values only change keeping the training dataset more or less constant.
rf = RandomForestClassifier(n_estimators=10, warm_start=True)
rf.fit(X_train, y_train)
rf.n_estimators += 5
rf.fit(X_train, y_train)From the above sample code, the initial model is trained with n_estimator=10 for X_train sample data. Then we further add 5 more trees n_estimator=5 and retrain the same model.
Follow one of my previous articles on incremental learning to get a better understanding of incremental learning and warm_state functionalities.
7.) Distributed Libraries:
Python packages such as Pandas, Numpy, Scikit-Learn provides high-level usable and flexible API but largely ignore performance and scalability. These libraries may cause memory issues while working with out-of-memory datasets.
The idea is to use distributed libraries such as Dask, Vaex, Modin, and many more, that are built on top of Pandas, Numpy, and Scikit-learn libraries and specially designed to scale up the workflow by parallelizing the operations across all the CPU cores.
Please find below the list of my previous articles on distributed libraries such as Dask, Vaex, and Modin:
8.) Save Objects as Pickle Files:
Reading and saving data or temporary files become tedious tasks while working with large datasets. Reading and writing operations for CSV, TXT, or excel data formats are computationally expensive.
There are other data formats that have comparatively faster read and write operations, that can be preferred while working with large-size datasets.
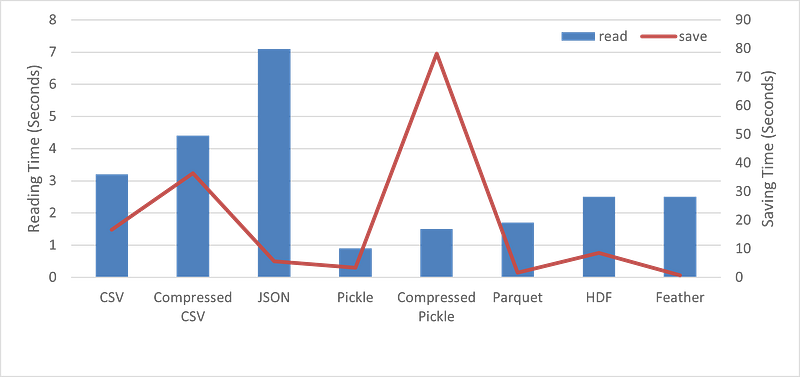
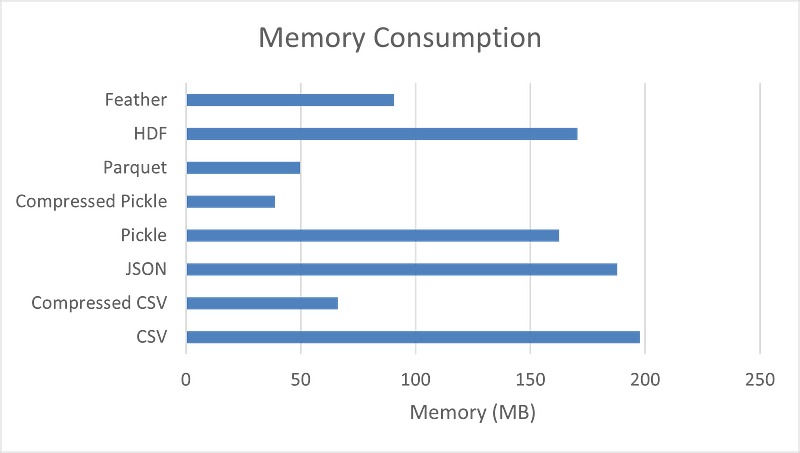
The above image shows benchmark numbers for reading, write operations and memory consumption for the sample dataset having 1,458,644 records and 12 features.
Pickle files can be preferred for saving and reading datasets or temporary files. Pickling can store python objects such as lists, dictionaries, class objects, and more.
Read one of my previous articles, to observe the benchmark time comparison of using various data formats for reading and saving operations
Conclusion:
In this article, we have discussed 8 various techniques or hacks that can be used while working with out-of-memory or large-size datasets. These techniques can speed up the workflow and avoid memory issues.
References:
[1] Scikit-learn Documentation: https://scikit-learn.org/0.15/modules/scaling_strategies.html
Loved the article? Become a Medium member to continue learning without limits. I’ll receive a small portion of your membership fee if you use the following link, with no extra cost to you.
Thank You for Reading





