
10 Examples to Master Distribution Plots with Python Seaborn
Distribution plots are of crucial importance for EDA

The first step of any data product should be understanding the raw data. For successful and efficient products, this step occupies a substantial part of the entire workflow.
There are several methods used for understanding and exploring the data. One of them is creating data visualizations. They help us both explore and explain the data.
By creating appropriate and well-designed visualizations, we can discover the underlying structure and the relationships within the data.
Distribution plots are of crucial importance for exploratory data analysis. They help us detect outliers and skewness, or get an overview of the measures of central tendency (mean, median, and mode).
In this article, we will go over 10 examples to master how to create distribution plots with the Seaborn library for Python. For the examples, we will use a small sample from the Melbourne housing dataset available on Kaggle.
Let’s start with importing the libraries and reading the dataset into a Pandas data frame.
import pandas as pd
import seaborn as sns
sns.set(style="darkgrid", font_scale=1.2)df = pd.read_csv(
"/content/melb_housing.csv",
usecols=["Regionname", "Type", "Rooms", "Distance", "Price"]
)df.head()
The dataset contains some features of the houses in Melbourne along with their prices.
The displot function of Seaborn allows for creating 3 different types of distribution plots which are:
- Histogram
- Kde (kernel density estimate) plot
- Ecdf plot
We just need to adjust the kind parameter to choose the type of plot.
Example 1
The first example is to create a basic histogram. It divides the value range of continuous variables into discrete bins and shows how many values exist in each bin.
sns.displot(
data=df,
x="Price",
kind="hist",
aspect=1.4
)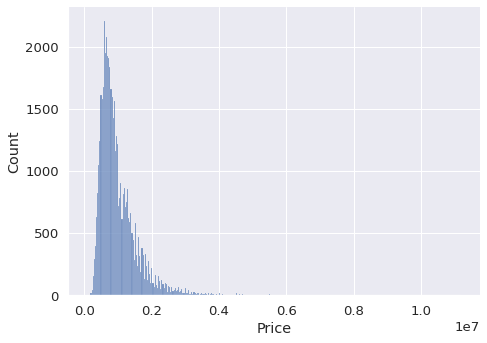
We pass the name of the data frame to the data parameter. The x parameter takes the column name to be plotted. The aspect parameter adjusts the width-height ratio of the size. It is possible to change the height as well.
Example 2
In the first example, we clearly see that there are outliers in the price column. The histogram has a long tail to the right which indicates there are few houses with very high prices.
One method to reduce the effect of such outliers is to take the log of values. The displot function can perform this operation using the log_scale parameter.
sns.displot(
data=df,
x="Price",
kind="hist",
aspect=1.4,
log_scale=10
)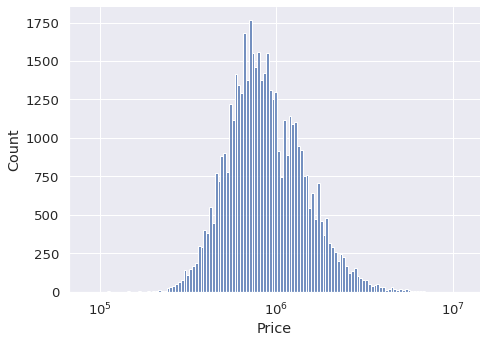
The price is represented as the power of 10. We now have a better overview of the distribution of house prices.
Example 3
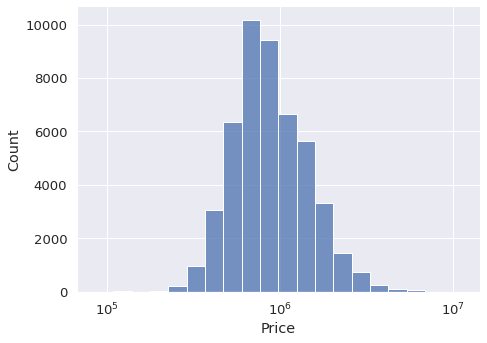
We can also adjust the number of bins in the histogram. In some cases, it is preferred to have less number of bins so that we get a more structured overview.
The parameter to use for this adjustment is the bins.
sns.displot(
data=df,
x="Price",
kind="hist",
aspect=1.4,
log_scale=10,
bins=20
)
Example 4
The dataset also contains categorical variables. For instance, the type column has 3 categories which are h (house), t (town house), and u (unit). We may need to check the distribution of each type separately.
One option is to show them with different colors in the same visualization. We just need to pass the name of the column to the hue parameter.
sns.displot(
data=df,
x="Price",
hue="Type",
kind="hist",
aspect=1.4,
log_scale=10,
bins=20
)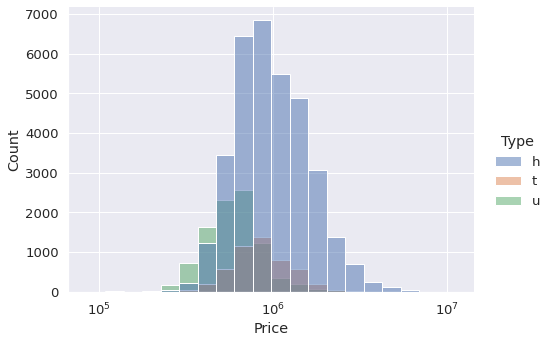
This plot provides us with 2 pieces of information:
- The size of each category with regards to the number of houses. The h category is the largest one.
- The price distribution of the houses in each category.
Example 5
Another option to check the distribution for each category separately is to create separate plots. We can either use the col or row parameter for this task. There will be a subplot for each category in the given column.
sns.displot(
data=df,
x="Price",
col="Type",
kind="hist",
aspect=1.4,
log_scale=10,
bins=20
)
Example 6
The displot function also allows for generating 2-dimensional histograms. Therefore, we get an overview of the distribution of the observations (i.e. rows) with regards to the values in 2 columns.
Let’s create one using the price and distance columns. We just pass the column names to the x and y parameters.
sns.displot(
data=df,
x="Price",
y="Distance",
col="Type",
kind="hist",
height=5,
aspect=1.2,
log_scale=(10,0),
bins=20
)
The darker regions are more dense so they contain more observations. Both columns seem to have a normal distribution because the dense regions are in the center.
You may have noticed that we used a tuple as the argument for the log_scale parameter. Thus, we can pass a different scale for each column.
Example 7
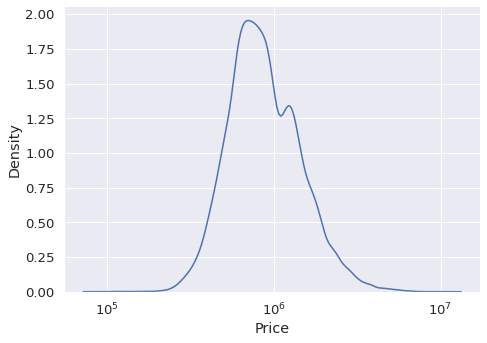
Kde plots can be used for visualizing the distribution of variables as well. They are quite similar to the histograms. However, a kde plot represents the distribution using a continuous probability density curve rather than with discrete bins.
The kind parameter is set as “kde” to generate kde plots.
sns.displot(
data=df,
x="Price",
kind="kde",
aspect=1.4,
log_scale=10
)
Example 8
Similar to the histograms, kde plots can be drawn separately for different categories. Our dataset contains region information of the houses. Let’s check how price changes in different regions.
sns.displot(
data=df,
x="Price",
hue="Regionname",
kind="kde",
height=6,
aspect=1.4,
log_scale=10
)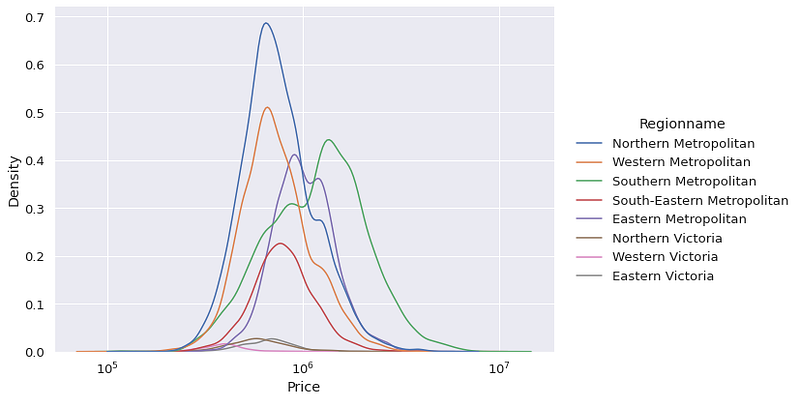
Southern Metropolitan region seems to have the highest average house price.
Example 9
Another method for checking the distribution of a variable is using an ecdf plot. It represents the proportion or count of observations falling below each unique value in the given column.
It is kind of visualizing the cumulative sum. As a result, we are able to see the more dense value ranges.
sns.displot(
data=df,
x="Distance",
kind="ecdf",
height=6,
aspect=1.4,
stat="count"
)
The value ranges in which the slope of the curve is high are populated with more observations. For instance, we do not have many houses with distance higher than 30. Contrary to this, there are lots of houses in the distance range between 10 and 15.
Example 10
The ecdf plots support hue, col, and row parameters as well. Therefore, we can distinguish the distribution between different categories in a column.
sns.displot(
data=df,
x="Distance",
kind="ecdf",
hue="Type",
height=6,
aspect=1.4,
stat="count"
)
Conclusion
For data analysis or machine learning tasks, it is very important to learn about the distribution of variables (i.e. features). How we approach given tasks may depend on the distribution.
In this article, we have seen how to use the displot function of Seaborn to to analyze the distribution of price and distance columns.
Thank you for reading. Please let me know if you have any feedback.



