
實作理解Diffusion Model: 來自DDPM的簡化概念
生成模型 (Generative Model) 網路一直都是 machine learing中熱門的題目。除了過往的幾年中常被提起的 VAE (Variational Auto-Encoder)與 GAN (Generative Adversarial Network),近年崛起、或者說復辟成功的其中一個方法就是擴散模型 (Diffusion Model)。
啟發於非平衡態熱力學 (Non-Equilibrium Thermodynamics), diffusion model是一個透過變分推斷 (Variational Inference) 訓練的參數化馬可夫鍊 (Markov Chain),並且在許多任務上展現了超越 GAN的效果,其中最知名的應用莫過於 OpenAI的 DALL-E 2與 Google Brain的 Imagen。這篇文章主要會藉由DDPM (Denoising Diffusion Probabilistic Models) 簡化概念,以比較概念式的方法來介紹 diffusion model的原理與實作。

文章難度:★★★★☆ 閱讀建議: 這篇文章是 diffusion model入門、概念式的介紹,雖然說是入門介紹,但因為 diffusion model牽扯到太多數學原理,因此內容還是會有些數學。整篇文章前半段介紹 generative model與 diffusion model,整體上是比較親民的部分;後半段則是 diffusion model的背後機率原理以及實作,相比數學原理,實作的部分反而是相當簡潔,可以交互參考看一下。若真心想理解完整數學,請在參考最後的細節指引。 推薦背景知識: Machine Learning, Deep Learning, Generative Model, VAE (Variational Auto-Encoder), GAN (Generative Adversarial Network), Normalizing Flow, Maximize Likelihood Estimation (MLE), Density Estimation, Markov Chain, Score Matching, Variational Inference.
Generative Model
以統計的角度來看,
生成模型 (generative model)的目標是 modeling目標資料的分布。
比如說,我們手邊有一萬張人臉的照片,但我們希望可以獲得更多人臉的照片,或者說想要依照某些情境生成更多人臉的照片。而使用 generative model來 modeling目標資料的分布,可以確保生成出來的是人臉的照片,而不是貓狗的照片,或是四不像的照片。
不考慮條件的 generative model的概念大致如下圖,首先會從一個已知的分布中採樣,將樣本放到 generative model生成目標資料,最後要讓這些生成資料的分布與真實資料的分布越接近越好。
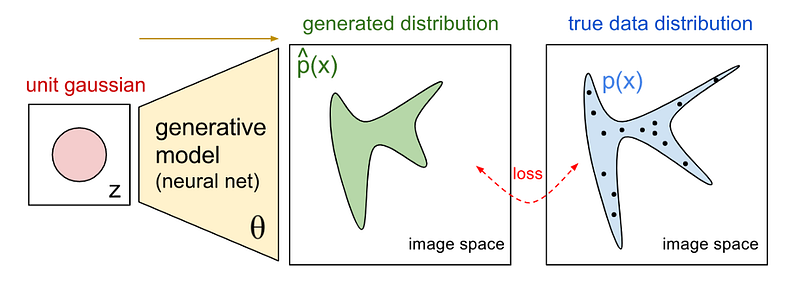
很直覺地,要讓兩種資料的分布接近,也就是 maximize likelihood estimation (MLE),或說 minimize some divergence。但描述真實資料的分布其實就是一個很難的問題,更遑論計算什麼 likelihood或 divergence。
Variational Auto-encoder (VAE)
在 generative model上,除了這幾年知名的 GAN (Generative Adversarial Network (GAN) [1]) 外, Variational Auto-Encoder (VAE) [2]也是一個常見的方法。
VAE對於大多搞 deep learning的是最好理解的。基於 auto-encoder,透過一個網路將輸入 x變成一組編碼,再透過另一個網路解碼回 x達成 unsupervised target。除此之外,VAE在編碼時額外讓已知的機率分布介入,限制編碼的範圍,這樣訓練完成後就可以透過採樣出來、不同的隨機值生成資料。
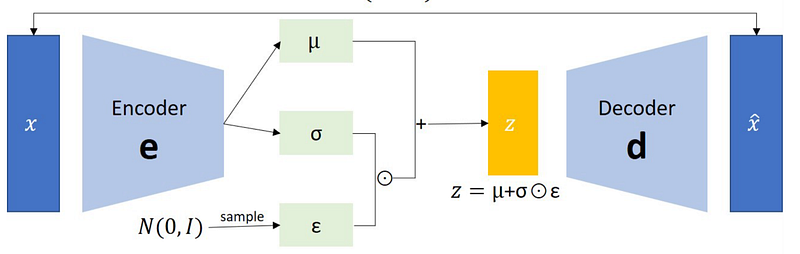
這邊特別介紹一下 VAE是因為 diffusion model與 VAE的 objective function有點相似,都是藉由 variational lower bound。有興趣可以先參考一下 CMU的課程投影片 [3],或李宏毅老師的課程錄影 [4]。
Diffusion Model
其實 diffusion model [5] 的崛起與 normalizing flow有點相似,其實都並不是非常非常新的方法,但都在近期因為某些改良,獲得了相當好的結果。
我們可以先從簡單的 image synthesis來看 diffusion model的經典案例,以下內容主要基於2020年經典的 "Denoising Diffusion Probabilistic Models",簡稱 DDPM [6]。

Diffusion & Learn How to Denoise
Diffusion model的核心精神是學習一個逐步denoise的過程。
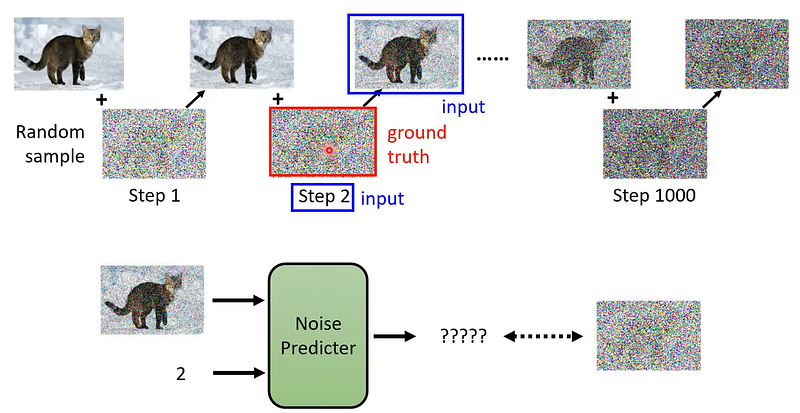
在訓練模型時,逐步地將原圖加入雜訊。具體上來說,使用一個高斯分布一次又一次地在原圖上打上很小的雜訊,然後讓網路來學習如何reverse這個雜訊。

Markov Chain
在開始推論整個 diffusion model的訓練之前,我們先概念式地看一下 diffusion model背後的一些理論基礎。在 DDPM中完整的定義是:
"Diffusion probabilistic model is parameterized Markov chain trained using variational inference to produce samples matching the data after finite time."
這邊直接放了原文,因為原文描述雖然有點多名詞,但十分精準。
總之,我們先不管 variational inference做了什麼 (晚點在說)。 Diffusion model就是一個參數化的 Markov chain。而所謂的 Markov chain簡單來說就是定義了一系列發展或演變會隨時間進行而呈現出不同可能的自然或社會現象,而這每個時間點的現象或狀態,就稱為狀態空間。
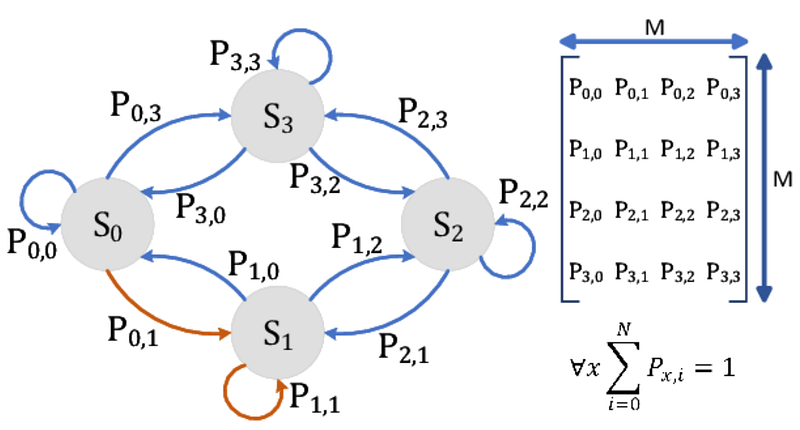
如果對這塊不熟悉只要先了解這個大概念即可,然後記得兩件事:
- Markov chain當前的任何狀態轉變的機率,都與過去狀態完全無關。
- 因此,假設有 k個狀態,我們可以列出一張 k×k的矩陣,定義這些狀態之間互相轉換的機率,稱為 stochastic matrix或 transition matrix。
至此,我們可以把 diffusion model過程的每個影像表示為 Markov chain。而訓練中加入很小的高斯雜訊則是來自 Gaussian noise。而網路 θ要學的東西就是如何 dinoise,或者說是stochastic matrix。

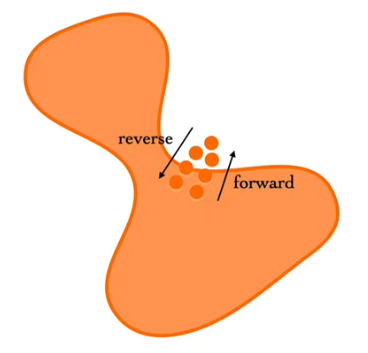
從這個角度來看,我們也可以想像整個訓練 diffusion model的過程,就將某筆資料從原本資料集形成的 manifold中一步一步推到邊界之外,然後訓練一個 model再把它推回來。而這之中的每個過程的暫態 ( x_0到 x_T),包含原圖與diffusion完的某個雜訊,都是 Markov chain中的狀態空間。
Common Implementation
到這邊聽起來好像有點複雜了,但實際上 diffusion model 的設計多半反而是簡單粗暴的。網路輸入通常為要被 denoise 的圖片以及現在是 denoise 的第幾個步數。而輸出通常是這步 denoise 完的圖片,或是說預測這步被加入的 noise。
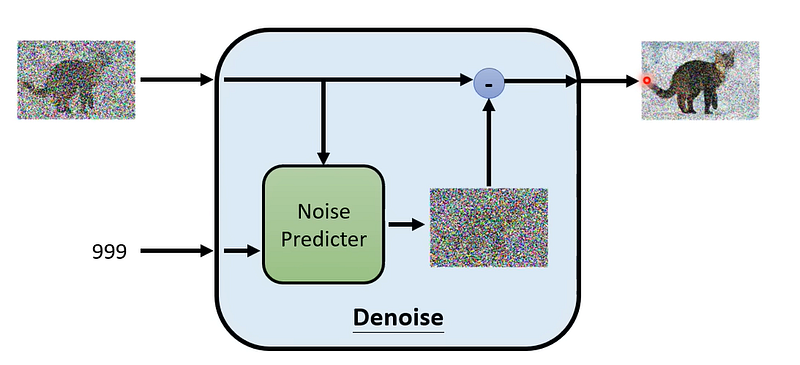
Optimizing Diffusion Models
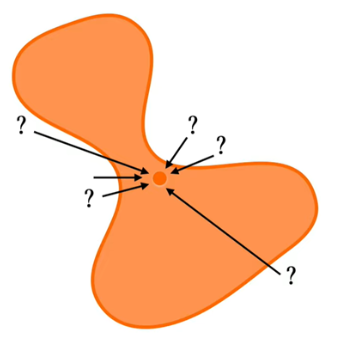
文章至此看來, diffusion model概念其實沒有很困難。但真正難的問題則是整個訓練到底要 optimize什麼?即使知道我們每次在圖片中打下的雜訊是來自高斯分布,但仍然無法知道實際上網路的訓練目標到底要怎麼寫。
或者更簡單地透過剛剛 manifold的例子想像一下,將一個在 manifold外的狀態空間 (即雜訊) 推到 manifold內的路線有無數種,如果要直接計算 maximum likelihood根本是天方夜單。
簡單的情況
雖然從數學上看起來是很困難的事情,但在 DDPM 的結果中,其實這個訓練方法非常的簡單。DDPM 最終的簡化後的結果是拿過程打的 Gaussian noise 直接計算 L2 loss 。
Variational lower bound
但所有 ML 訓練的背後,通常都有一套數學依據。 DDPM 的訓練方法確實就像 VAE 一樣簡單,但有心想深究 diffusion model ,還是需要理解為什麼直接對網路預測的 noise計算 L2 loss可以是有效的 loss function。
背後的理論就是 Variational lower bound。
一言以蔽之, variational inference是一種近似複雜分佈的數學方法。而在 deep learning中最知名的一個情境就是訓練 VAE時使用的 variational bound on negative log likelihood。
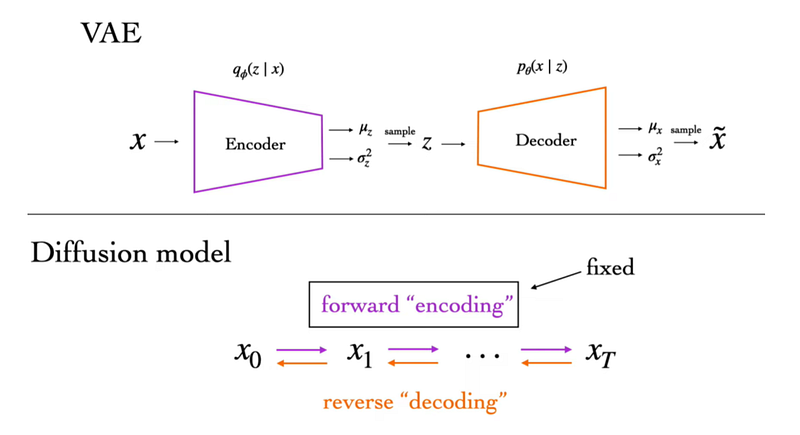
Diffusion model的過程其實跟 VAE有幾分相似,我們可以把 diffusion model想像成一個 encoder是固定的 VAE,然後對每個停下來的點都可以當成是 VAE裡面的 latent z,那就可以用跟 VAE的 variational lower bound寫出 p(x)的 lower bound。
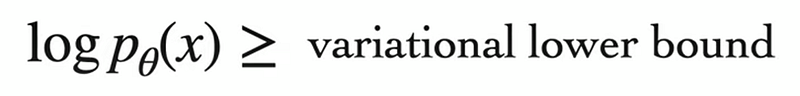
至於這個variantional lower bound要如何推導到最終的loss function還有一段路,而且挺麻煩的。不過實際上訓練 diffusion model時要寫的程式碼其實跟 VAE一樣非常簡單。以下就會依序從 diffusion model訓練時的幾個步驟介紹一些數學式與實際的程式碼。
註:因為這邊的數學要完整推導很麻煩,所以內容比較偏向解釋為什麼這樣可以訓練,而不是真正的細節推導。以下數學式大多截圖自原作者論文、 Ari Seff的 Youtube影片 [7]、以及 Lil’Log的 Blog [8],為了內容簡潔,就不逐一標示了。
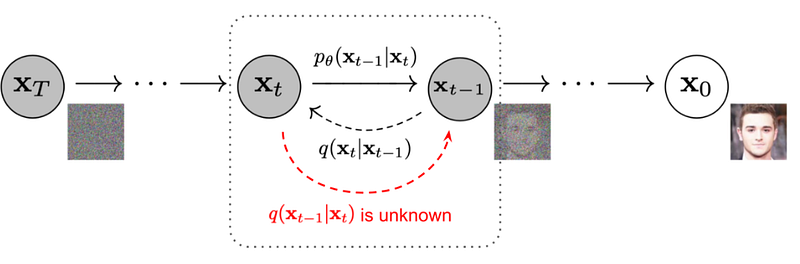
Forward diffusion process
首先,基本上 forward process的行為就是一個逐步加上高斯雜訊的 Markov chain。想像一張圖片 x_0,從原本特徵清晰可見的情況,逐步使用 q加上雜訊,直到變成幾乎不存在特徵的一張雜訊圖 x_T。我們可以先試著將任兩個連續 state的轉換寫作:
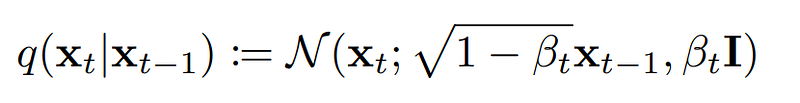
式子中的 β稱為 variance schedule,可以說是控制每一次加入雜訊的參數 (或固定為超參數) 。
而走過整個 Markov chain,即從state x_0 走過state x_1, x_2, …, 到 x_T的機率可以寫作:
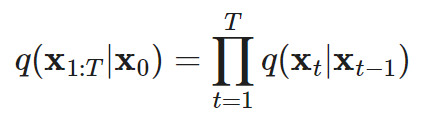
也許對一些應用派的 DL人員來說,看到這樣的數學就有點眼花撩亂了,但其實他的時作相當簡單,整個 q的計算不過就很標準的幾行程式。

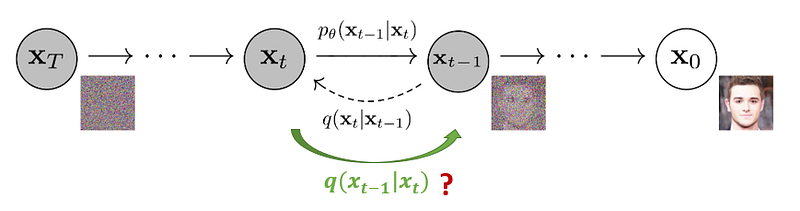
Reverse diffusion process
要反過來進行reverse diffusion process時,其實就是去估算 p。而實踐 p_θ 時有很多不一樣的方法,在 DDPM的推理時有一個假設是每次加入的雜訊 q都是一個高斯分布,並且這個分布的 variance很小。而當 q是高斯分布且 variance很小時,p也會是一個高斯分布。
因此 DDPM直接讓網路 θ來預測高斯分布的 mean與 variance。
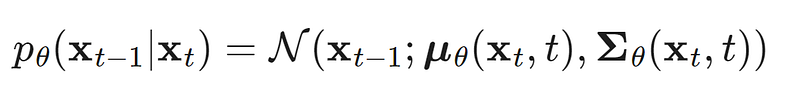
當然同理,從純高斯雜訊 x_t走回 x_o的過程可以寫作連乘,即從state x_T 走過state x_(t-1), x_(t-2), …, 到 x_0的機率:
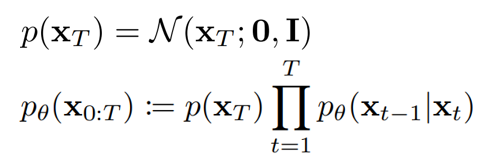
Training target
接下來我們回想一下我們的訓練目標,也就是透過 variational lower bound:
對lower bound做一些簡化後,我們可以得到 loss term大概長這樣:
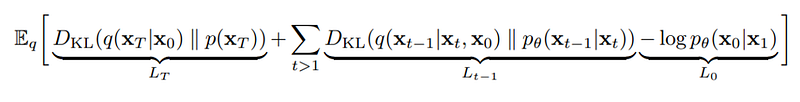
先暫時不管這個簡化跟最終這個 loss term的細節,先看一下 loss term裡有一個對 t>1都要計算的 KL divergence,可以把它想像為這個 Markov chain中每兩個相鄰的 states都要計算一次,而這其實蠻麻煩,也很花時間。
不過實際上我們也不需要真的一步一步地來計算,通過一些精巧的數學推導 (reparameterization trick) 後,逐步加上高斯雜訊的過程可以被一步計算:
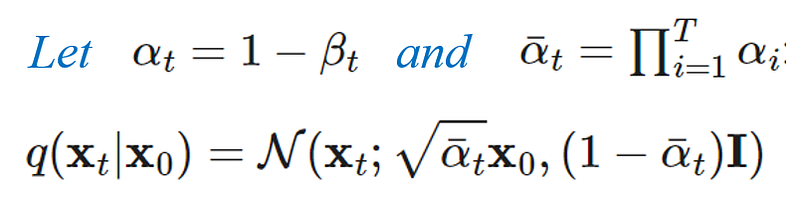
最後, DDPM的訓練目標異常的簡單,經過一連串的 repaarameterization、化簡與假設後, loss term就是直接對網路預測的 noise計算 L2 loss。
簡單來說就是把剛剛列出的三項loss term,逐步幹掉:
- 左邊項裡其實不帶任何可訓練參數
θ,省略。 - 中間項因為高斯雜訊的過程可以被一步計算,移除 summation。
- 右邊項等於影像的第一次做的transform,這邊直接把他從訓練過程中拿掉 (可以把他理解成固定已知的normalization)。
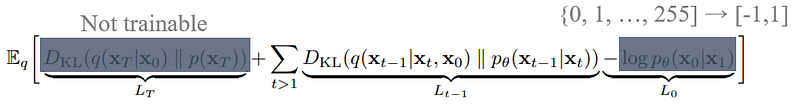
最後就剩下中間項,而中間項則是我們之前說不會算的倒過來的機率。
不過很有趣的是,當這個條件機率基於 x_o時,透過貝氏法則可以轉換為都是已知的部分:
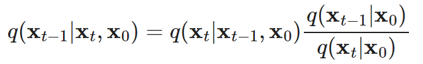
最後整理一下,化簡出來是個高斯分布:
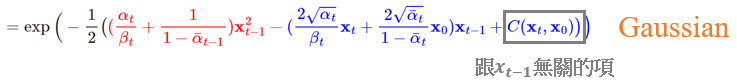
至此,其實我們的 loss就是兩個高斯分布的 KL divergence,因此可以在closed form expressions中有效率地計算。
Final Training Loop
實際上 DDPM論文在實驗中發現 variance直接固定,訓練起來反而比較穩定。
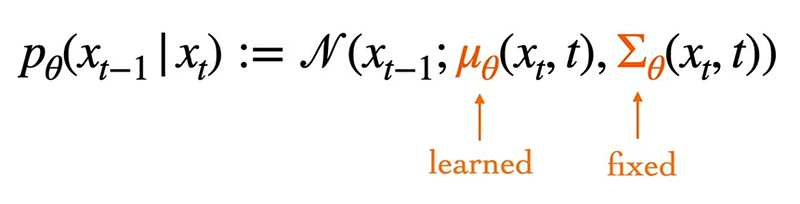
因此實作上,網路 θ是直接去預測一張與輸入同樣維度的高斯分布 ε_θ。而 q(x_t|x_0) 也可以被重寫為ε的形式:
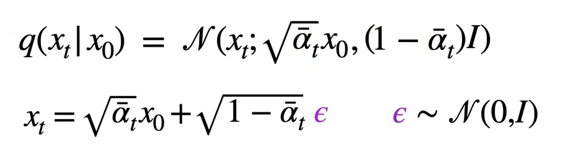
因此最終的 loss可以簡化兩個 ε 之間的 weighted l2 loss。
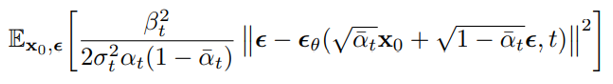
但論文發現省略這個 weight反而可以幫助網路更加集中在較困難的 sample,因此最終 loss直接寫作:
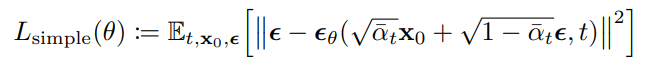
對比一下原論文的 training algorithm,會更加清楚這邊到底在幹嘛。

Generating Samples
至於執行生成任務上, unconditional sampling就是從一堆 noise開始, iteratively把圖片丟進網路,然後持續讓 sample變得清晰,直到滿意為止。
原則是跑越多 iteration,效果越好。

當然,這也是 diffusion model的一個問題, sampling的時候太花時間了。
這篇文章關於 diffusion model的理論介紹就到這邊了。再次聲明,上面所牽扯到的數學推導真的太過於複雜,因此內容比較偏向解釋為什麼這樣可以訓練,而不是真正的細節推導。如果對於真正的推導有興趣,務必參考原論文、 Ari Seff的 Youtube影片 [7]、以及 Lil’Log的 Blog [8],這邊有數百行的數學細節推導。
其實本身寫這篇也是寫得戒慎恐懼,生怕寫錯得不夠精確。如果有讀者看到描述不當或是不正確之處,歡迎協助指證,感謝!
[2023.04.16 補充] 近期李宏毅老師也上片解釋 diffusion model,有十來分鐘的概念版本,也有近一小時的細節版本。也推薦大家透過這些影片資源學習。
當然也不得不提一下,雖然這邊都在討論的是 unconditional image synthesis,不過其實 diffusion model這一年特別紅的原因是在有 condition的生成情境,特別是在將其他 semantic資訊生成圖片的任務,比如說從一句話生成圖片。
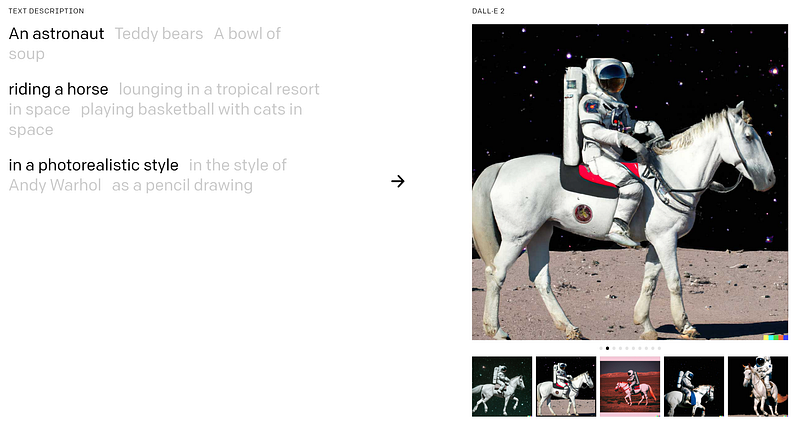

有的時候真的很難想像這些圖片生成任務,能夠從文字中將這些 latent space與影像連結,並且成功的生成出這些根本不存在的圖片。
Diffusion model在數學上最有意思的地方是精巧地利用 Markov chain與 tractable的分佈,在 generative modeling上同時展現了兩個通常需要 trade-off的特徵: tractability與 flexibility。簡單來說就是好不好算與模型表述能力強不強,確實在 PGM (probabilistic generative model) 上這兩個特徵很常是對立的。
但 diffusion model的問題也是有的,先撇除與 VAE一樣的 ELBO (evidence lower bound)。最顯而易見的問題還是整個 sampling的過程還是需要走過不短的 Markov chain,這也導致了較長的運算時間。雖然後續已逐漸有加速方法,但目前整體來說還是比一般的 GAN慢。
但不論是 VAE、 GAN、 NF、本文討論的 diffusion model,又或是更簡單的 GMM,其實都是有他們強大與適用的一面,而這之中許多模型也同時都在快速地演化、發展中,因此並不能直接斷言其中存在一個最強者。
好了~這篇文章就先到這邊。老話一句,Deep Learning領域每年都會有大量高質量的論文產出,說真的要跟緊不是一件容易的事。所以我的觀點可能也會存在瑕疵,若有發現什麼錯誤或值得討論的地方,歡迎回覆文章或來信一起討論 :)
Related Topics
Reference
[1] Generative Adversarial Networks [NIPS 2014] [2] Auto-Encoding Variational Bayes [ICLR 2014] [3] Variational Autoencoders [slides from CMU] [4] ML Lecture 18: Unsupervised Learning — Deep Generative Model (Part II) [YouTube] [5] Deep Unsupervised Learning using Nonequilibrium Thermodynamics [ICML 2015] [6] Denoising Diffusion Probabilistic Model [NeurIPS 2020] [Project] [7] What are Diffusion Models? [Youtube] [8] What are Diffusion Models? [Blog Lil’Log] [9] AIAIART Lesson #7 — Diffusion Models [Youtube] [Colab Note] [10] Generative Modeling by Estimating Gradients of the Data Distribution [Blog by Yang Song] [11]DALL·E 2 is a new AI system that can create realistic images and art from a description in natural language. [OpenAI] [12]Imagen: unprecedented photorealism × deep level of language understanding [Google Brain] [13] Hung-Yi Lee 生成式AI 淺談圖像生成模型 Diffusion Model 原理 [Youtube]





