
語言雜談:歐陸數字散步

之前在 Medium 看了華田 Watin 有關 quarantine 語源的文章,也碰巧在 Twitter 看到了有人在爭論 quarantine 是來自意大利語 14 還是 40,想起數字和語言之間有際的關係。作為喜歡 learn and learn about languages、在學語言時收集和語言有關的冷知識者,小妹自然想寫些有關數字的二三事。
都是同源的 1–10
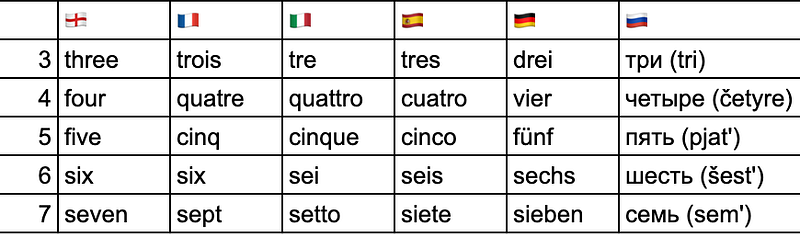
如果大家除了英語外,有學習其他歐洲語言的話,我想大家應該都曾經好奇,為何有些數字在不同語言的讀法如此接近,有些卻差天共地。例如不同語言的 3 字後方的母音未必一樣,但都一致地以 tr/dr 開頭;又或者大家的 6 的唸法都頗接近。然而 4 和 5 卻是如下圖般,壁壘分明地分了日耳曼、羅曼和斯拉夫的三條隊。
這麼說來,自己剛學法語時還真的想過,會不會是有一種語言把自己的數字「輸出」到其他的語言去了,例如英語、德語的 6,會不會都是從拉丁語或是法語借去,所以才都是 six 的拼法/讀音——當然事實並非如此,三種語言的 6 的近似,是因為它們是上承自同一祖先原始印歐語 (Proto-Indo-European)。
真正有規模的數字輸出,還得數到把大半套或全套 1–10,輸出到韓語、日語、泰語和越南語的上古、中古漢語。此外 0 也是個有趣的例子,由於歷史上歐洲人接受「零」是數字的概念,還是比較晚期、在近一千年以內的新奇事。所以不少語言的 0,其實是隨著零的概念從阿拉伯語傳入歐洲語言的。
回到上面有關 6 的問題。雖說印歐語系的語言都是承繼同一祖先,但它們在經歷各種音變,以及被各國透過訂立正寫法規管後 (英語是少數的例外),這些源自同一祖先的數字詞,到了現代便變得拼起來差很遠、唸起來差很遠、或是兩者都差很遠了。
部分自己較有印象的趣談:
- 英語「one」那個 /w/ 音最先出現於英格蘭西部、西南部方言,並在十八世紀成為了標準。One 的發音自此和荷蘭語、德語的 een、eins 脫隊。
- 雖然英語 one 是受法語 on 影響而衍生出不定人稱代名詞的用法,但兩者在語源上無關。法語 on 是由拉丁語的 homo (人) 而來,而將「人」字當成不定人稱的用法,則是受其他日耳曼語族成員影響,例如德語 man。
- 上圖的 4 在羅曼語族很一致的都是 /k/、/kw/ 音,但進入日耳曼語族則變了 /f/、/v/。語言學家的假說,是 4 在原始日耳曼語階段,已經被旁邊的 5 的 f 音影響,使這 f 音被帶到 4 去了。當然這些重構出來的唸法,是透過比較同一字詞在各衍生語言的發音所得出的假說,科學家沒有也不能確定這些數字在遠古時代的讀音,而部分重構假說亦存有爭議。由於小妹並非相關領域學生、研究員,在此沒有代大家 fact-check 的資格,所以先就此打住。
- 在北日耳曼語支中,只有瑞典語的 7 sju 以及挪威部分方言演變出了臭名昭著的 sj/sk 音 /ɧ/,其他成員都還保持了 /s/ 音開頭。IPA 表示這個 /ɧ/ 是同時發的 /ʃ/ (平時英語的 sh) 和 /x/ (德語 Bach, Buch 的 ch),但實際上這個 /ɧ/ 怎麼發,似乎還是得看/聽真人示範來了解。
- 法語的 neuf 除了 9 之外的另一個意思是「全新」。「九」的 neuf 源自拉丁語 novem,而「新」的 neuf 則源自 novus;Novus 同時也是法語另一個解作「新」的形容詞 nouveau 的來源。所以巴黎地鐵那個月台牆壁上有很多錢的 Pont-Neuf 站不是九橋,是新橋。然而這「新橋」本身卻是塞納河上最古老的橋,建成於十七世紀初。
- 手上有本去年在芬蘭買的芬蘭語課本,所以也拿出來比較一下。芬蘭語是少數在歐洲內的非印歐語系語言。芬蘭語數字除了看來特別,我們還能從詞頭勉強看到,他們 8 和 9 都祭出了「(比 10) 少 2 和 1」的減法構成。但同樣 -än 結尾的 7 並不是 10–3,只是被 8 和 9 影響而衍生出的詞尾。幸運地芬蘭語在 10 之後的數字還是很規律的。而由於口語芬蘭語和書面語的分別並不小,這一串串數字在口語裡通常都會略去部分音節來讀出來。
- 和數字無關,但這裡可以多嘴一下,其實芬蘭語的 15 個格並無一般人說的那麼恐怖,因為芬蘭語大部分的格的作用其實就和其他語言的介詞 prepositions 無異,例如表達數量、位置、方向、手段、有無等。

詭異的 11 至 19
十位數是除了個位以外,各種語言還比較有自己特色的部分。到了百位之後,大家的表達方式基本上都一樣。而在 90 個十位數當中,11 至 19 在大部分語言中又較與別不同,和 20 之後的數字以不同的詞根構成,而中間又會以某個數字作分界:分界前的數字是一種砌法,分界後的又是另一種。
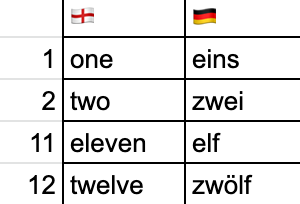
- 英語、德語等日耳曼諸語的 11、12 都是以無法分辨出字根的形式拼寫,但從詞頭我們仍能隱約看到 1、2 的痕跡,而剩下的部分的語源是「剩下」,也就是數到 10 之後還剩下 1、2 之前。至於為何沒有剩下 3、4、5?這是因為遠古時代人們沒有太大需要去接觸比 10 更大的數,所以不會數得比 10 多太多。而 12 也許是因為其能被多個個位數整除的「有用」特性,而使得古人更常會用到吧。而在後來才發展出的 13 之後的數字,它們使用的「個位+10」形式,還是十分清釋可見的。
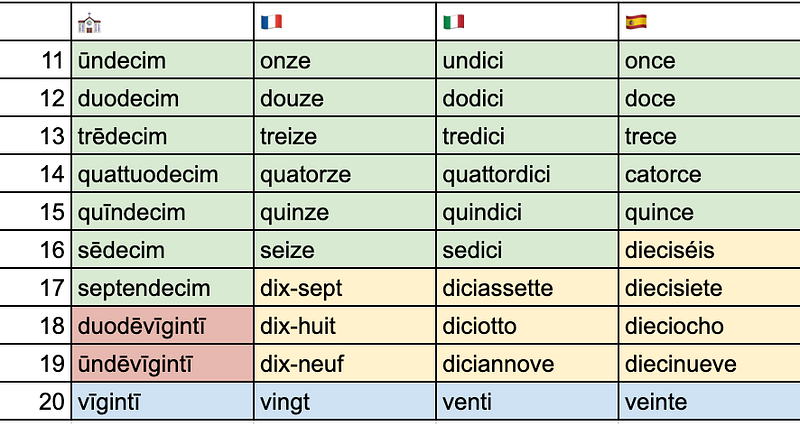
- 羅曼語族的發展則比較迴異:在 16 之前大家都是跟隨拉丁語,是「個位+10」的形式,但西班牙語、葡萄牙語在 16 已經變成了 10+6,而法語、意大利語則在 17 才變成 10+7,但祖上的拉丁語卻由 11 至 17 都是「個位數+10」,然後在 18、19 變成了「比 20 少 2/1」。雖然 8/9+10 的說話也存在於拉丁語,但通常會被視為俚俗、未受良好教育的象徵。羅馬尼亞語是唯一的例外,11 至 19 用的都是「個位+to+10」。
How many scores — 多少個二十?
- 20 在法語是 vingt,驟眼看來和後面那些 30、50 的 -ante 語尾有極大差異。但它們在還在拉丁語的時候,差異其實並沒有這麼大,尚且只是 20 vīgintī 和其他十的 -gintā 有點不同。
- 從 vingt 現時的讀音、古法語及拉丁語中 vint、vīgintī 的拼法可以看到,現代法語 vingt 的那個 g 是在制訂正寫法時,為了方便人們從拼法追溯其拉丁語語源、避免拼錯同音字 (例如解作「酒」的 vin) 而補回去的的,但是補錯了地方。而這些補回去顯示語源的字母,也是現代法語這麼多 silent letters 的一個原因。英語的一些字也有同樣情況,例如現代英語的 debt 就是從中古英語的 dette (和現代法語一樣拼法) 強行 downgrade 回去模仿拉丁語的 dēbitum。
- 同樣源自拉丁語的 vīgintī,意大利語的 20 是 venti。Starbucks 最大杯的尺寸叫 Venti,也是因為其分量正好是 20 安士。與人們認為 Starbucks 無法攻入意大利的想法不同,Starbucks 原來已在意大利開了 10 間店:米蘭 8 間分店、1 間旗艦店,都靈去年也開了 1 間分店。而比 Venti 小一級的 Grande 該怎麼讀,也曾是個困擾小妹一時的問題:薄扶林大學店的人,都習慣將之讀成「古蘭地」,使得小妹還躊躇過哪個才是正確唸法。
- 20 也經常出現於各種不同語言數數字的 meme 上,這主要是拜法語和丹麥語所賜,而丹麥語對二十進制的執著又要遠比法語強。也許法語的 80 是 4 個 20 quatre-vingts、99 是 4 個 20 加 19 quatre-vingt-dix-neuf,這些大家都耳熟能詳,但這在丹麥語面前也只是小兒科。除了 meme 上的 90=4.5×20 外,丹麥語的 30 到 90,除了 40 是「4 個 10」外,其他都是以「X 個 20」的形式組成!例如 50 就是 2.5 個 20,而且這些數字在拼讀兩方面都經過縮短,20 在字詞上幾乎不見其蹤跡。這也是一些教材會建議人們直接把數字背掉的原因,因為就算把詞源記下也對記憶沒幫助。追本溯源可以是之後的事,就像先背熟了 lundi、martedì 是星期一二後,再發現原來 lundi、martedì 就是月曜日、火曜日也不遲。
- 而在旁邊一眾「十位+個位」的語言包圍下,只有德語、丹麥語和荷蘭語是「個位+and+十位」的形式。乍看三者很奇怪,但其實他們才是保留了古日耳曼遺風。例如在丹麥、瑞典、挪威語的共同祖先古諾斯語 (Old Norse) 中,十位數並沒有固定的順序,先十後個或是先個後十都可以。而這自由排列也曾見於古瑞典語、近代英語 (例如 four and twenty),但隨著時間過去,這些用法也已被先十後個的形式完全取代,只餘下上述三者繼續是先個後十。
- 至於為何德語會堅持先個後十至今,可以追溯至馬丁路德在翻譯德語聖經時,決定保留了這傳統次序。而他的德語聖經作為現代德語的奠基石,也自然把這先個後十的次序流傳下來了。
- 由於挪威曾長期受丹麥統治,挪威語部分方言受丹麥語影響極深,也因此有人會在講挪威語時,跟隨了丹麥語的數字順序 (二十進制就不必了)。而丹麥人自己也曾有研究指出,丹麥語先個後十的順序以及 20 進制的十位數系統,對兒童學習數學造成障礙。
大數的概念
上面說到百位以上的數字,不同語言的表達方式基本上都一樣。而除了表達方式,它們表達的 100、1000 等意思的字,來源也一樣。有假說認為,古人在最初並不是真的把這些數字當成 100、1000 來使用,而只是用來表達「很大的數字」的意思,直至人類要掌握的數目增加了,他們作為 100、1000 的用法才固定了下來。這和漢字八、九雖然本義是 8、9,但有時能借代作「很多」的意思,是類似但相反的情況。
亦因如此,在原始日耳曼語以至 Old Norse 中,「一百」除了是 100,也可以是能夠整除更多數字的 120,即所謂 long hundred。而 short hundred 就是隨基督教文明而來的 100,而 short hundred 在最終完全取代了 long hundred。
而 hundred 的另一有趣之處是,hundred 後方「red」的部分,是從原始日耳曼語的階段開始出現的。只有現時成為「hund」的部分本來是解作 100,而「red」的部分本來是解作「數量」。
而在 100、1000 之上的下一個數字詞,是一百萬的 million。由 million 開始的數值,各種語言幾乎再也沒有任何分別了,最多就只有因語言而異的後綴,以及數學上的 long scale 和 short scale 之分。Long scale 是每一百萬倍才換一次前綴,例如一千個 Million 首先是 Milliard,再一千個 Milliard、也就是一百萬個 Million 才是 Billion。而 short scale 則是每一千倍就換一次前綴,也就是一千個 Million 就會升級作 Billion。本來英國和歐陸一直採用 long scale,而美國在殖民地年代則已引入 short scale,但英國從 1974 年起也轉用 short scale 了。
回到 million 的語源。由於人類都是在中世紀才出現要經常使用這些大數的必要,所以「million」這個字的誕生,已經是中世紀的事情。這字是由意大利語的 1000「mille」加上指大後綴 -one 來表示「一百萬真的很大」來構成的。之後的 billion、trillion 則是透過 reverse engineering、將 million 的 m 當成是 1 的前綴,再放上 bi-、tri- 等前綴而成。之後就再也沒甚麼特別的軼事了。
順帶一提,意大利語還有「grazie mille」來表示十分感謝的說法,用 2000 年代的香港網絡用語則是 THX*1000。Grazie mille!