
回歸分析(Regression analysis)的R平方(R squared)與調整後R平方(Adjusted R squared)
衡量回歸模型表現的兩個指標
R平方(R squared)
R平方(R squared)又稱為判定係數(coefficient of determination),是一種衡量回歸模型表現的指標,代表從獨立變數X可以解釋依變數Y變異的比例。
殘差平方和(residual sum of squares)
『可以解釋的部分』聽起來有點抽象,或許從『不能解釋的部分』來思考會容易許多,對於一個模型來說,什麼叫做『不能解釋的部分』?就是殘差(residual)。我們耳熟能詳的公式每個樣本點的真實值yᵢ-預測值fᵢ即為殘差,為了數學上計算的方便,在加總累計時通常我們都會取平方和,殘差平方和(residual sum of squares)公式如下
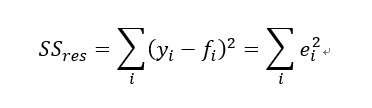
因此殘差平方和越大,表示模型解釋力越低,非常容易理解。
總平方和(total sum of squares)
殘差既然是不能解釋的部分,欲解釋的總變異量是什麼?我們以真實值-平均觀察值的平方和表示
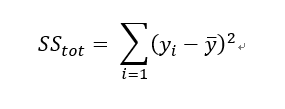
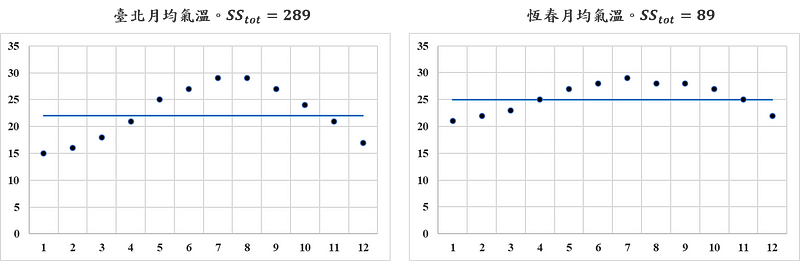
在此變異量可以想成是資訊含量,如果今天觀察值是常數,總變異量會是0,毫無資訊含量可言。下方是臺北及恆春的月均氣溫散布圖,藍色直線表示月均氣溫的平均值,依照公式計算臺北月均氣溫的總平方和(total sum of squares)為289,恆春地區則為89,舉該簡單例子讓讀者體會數據的變異程度對總平方和(total sum of squares)值的影響。
上述說明殘差平方和(residual sum of squares)就是『不能解釋的部分』,總平方和(total sum of squares)為『欲解釋的總變異量』,因此不能解釋的變異的比例為:
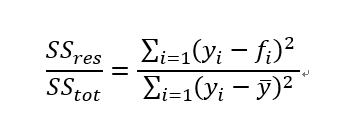
可以解釋的比例,自然就是以1去相減,就得到大家耳熟能詳的R平方(R squared)的公式。
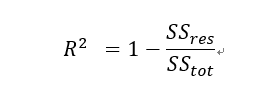
附註
事實上總變異平方和就是回歸平方和及殘差平方和的組成。

解讀R平方(R squared)
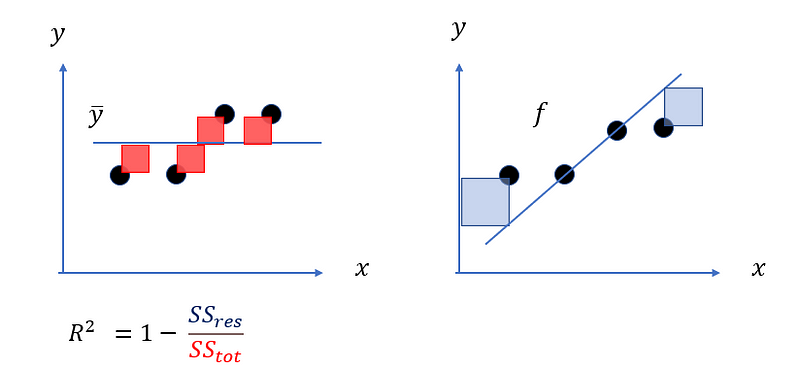
以上圖筆者繪製的一張圖來體會,左邊紅色正方形的面積總和就是依變數y的總變異量,計算方式是觀察點(圓心)與y bar的距離取平方的加總,代表我欲解釋的部分;右邊藍色正方形的面積加總,就是殘差平方和,為模型不能解釋的部分,計算方式是觀察點(圓心)與fi (預測值)的距離取平方的加總,殘差平方和越小,表示不能解釋的部分越小,則R平方自然越高,如果找到一條完美回歸線穿越所有資料點,使殘差變成0,R平方就會變成1,表示模型解釋所有變異量。因此,正常情況下R平方的值會落在[0,1]。
R平方有沒有可能是負的?
有,當模型的殘差平方合大於總變異量時,R平方就是負的,如下圖:
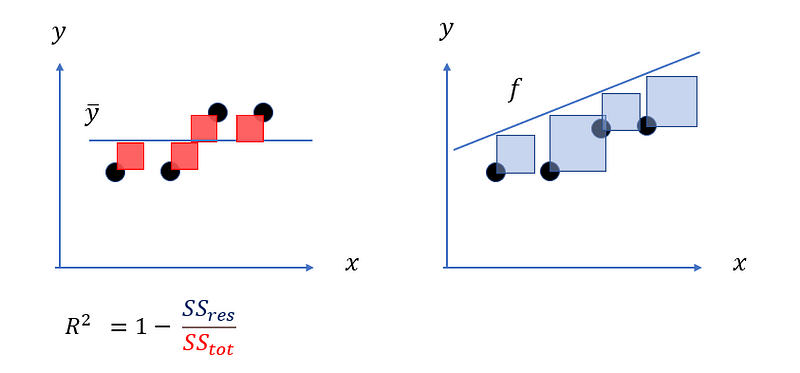
這表示模型完全沒有用處,預測效果比用平均值來猜測還要糟糕!
調整後R平方(Adjusted R squared)
R square越高越好?
當然不是。回想最小殘差平方和的表示如下:
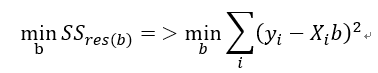
其中Xi是表示第i組解釋(獨立)變數的row vector,b則是對應X的係數;yi則是第i組的依變數。
理論上獨立變數X越多,殘差平方和只會越小,可以想像新增的一個X變數,即使對解釋目標y毫無貢獻,就使其係數變成0即可,因此殘差平方和最差就是打平,不會有反增的情況,在殘差平方和越小的情況,當然只會使R square變得越高。 R square變高本身是好事,代表解釋程度更高,但是放太多不重要的變數,會使得係數的估計變得不穩定(這裡會另外寫一篇推導估計係數的變異數)。
因此R平方不是一個客觀的指標,在此把變數的數量也納入考量,得到調整R平方(Adjusted R²),調整R平方可視為R²的不偏估計式,重新書寫如下:
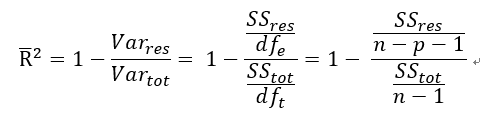
其中n為樣本數量,p為變數數量。這裡可以注意到,得到的調整R平方會小於R平方。






